Import von Daten in R

Maria Bobrowski
RLab - Skriptbasierte modulare Umweltstatistik (Universitätskolleg 2.0)
Universität Hamburg
RLab-Impressum
Gefördert im Rahmen des „Lehrlabors“ im Universitätskolleg 2.0 aus Mitteln des BMBF (01PL17033)

Dieses Digitale Skript von Maria Bobrowski, Universitätskolleg 2.0 / Lehrlabor, Universität Hamburg, ist lizenziert unter einer Creative Commons Namensnennung - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz.
elearn.js Template
Universität Hamburg
Das elearn.js Template von Universität Hamburg ist lizenziert unter einer Creative Commons Namensnennung - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz
Import von Daten in R
Maria Bobrowski
RLab - Skriptbasierte modulare Umweltstatistik (Universitätskolleg 2.0)
Universität Hamburg
CC BY-SA 4.0| 2017
Ziel
In diesem Skript erfährst Du, wie Du Dateien in R importieren kannst. Es wird Dir gezeigt, wie Du Comma-Seperated-Values-, Text- und Excel-Dateien importieren kannst.
Dabei werden Dir Hinweise zum Umgang mit den einzelnen Dateitypen gegeben und wie Du überprüfen kannst, ob die Dateien korrekt eingelesen wurden.
Voraussetzungen
Um dieses Skript zu verstehen, solltest Du
- R und RStudio installiert haben und
- RStudio mit R verbunden haben,
Das ist alles in Installation von R und RStudio beschrieben, schaue gegebenenfalls dort nach und kehre dann hierher zurück!
Für Anregungen und Kommentare zur Verbesserung ist das RLab-Team immer dankbar! Du kannst auch Fragen zu den Inhalten stellen! Nutze für all das gerne die Kommentar-Funktion!
Vorstellung der Dateitypen
Es gibt viele verschiedene Dateitypen, in denen die Daten abgespeichert sein können. In diesem Skript werden die drei häufigsten Dateitypen vorgestellt:
- Comma-Seperated-Values-Dateien (.csv) best practice
- Text-Dateien (.txt)
- Excel-Dateien (.xlsx oder .xls)
-
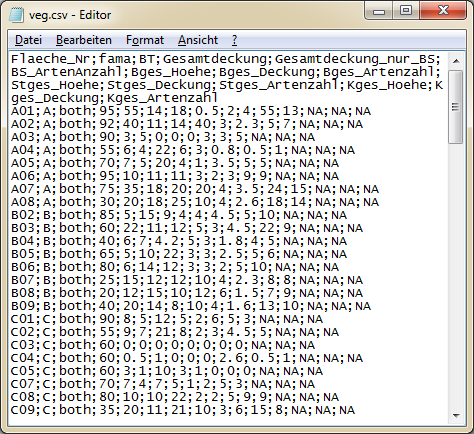
Hier ist eine Comma-Seperated-Values-Datei (.csv) im Windows Editor abgebildet, diese zeichnet dadurch aus, dass Spalten und Zeilen durch ein Trennzeichen (Separator) von einander getrennt werden. In diesem Fall ist das Trennzeichen ein Semikolon, es kann aber auch ein Komma oder ein Leerzeichen sein.
-
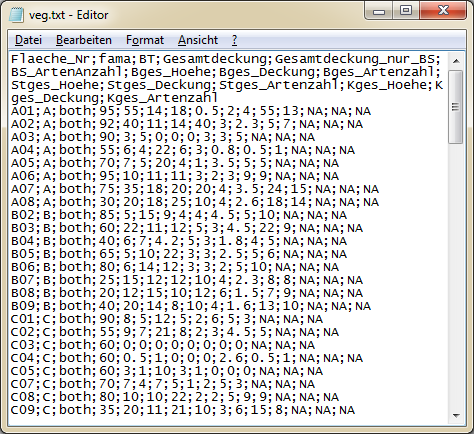
Hier ist eine Text-Datei (.txt) im Windows Editor geöffnet. Auch hier sind Spalten und Zeilen mit einem Trennzeichen (Semikolon) von einander getrennt.
-
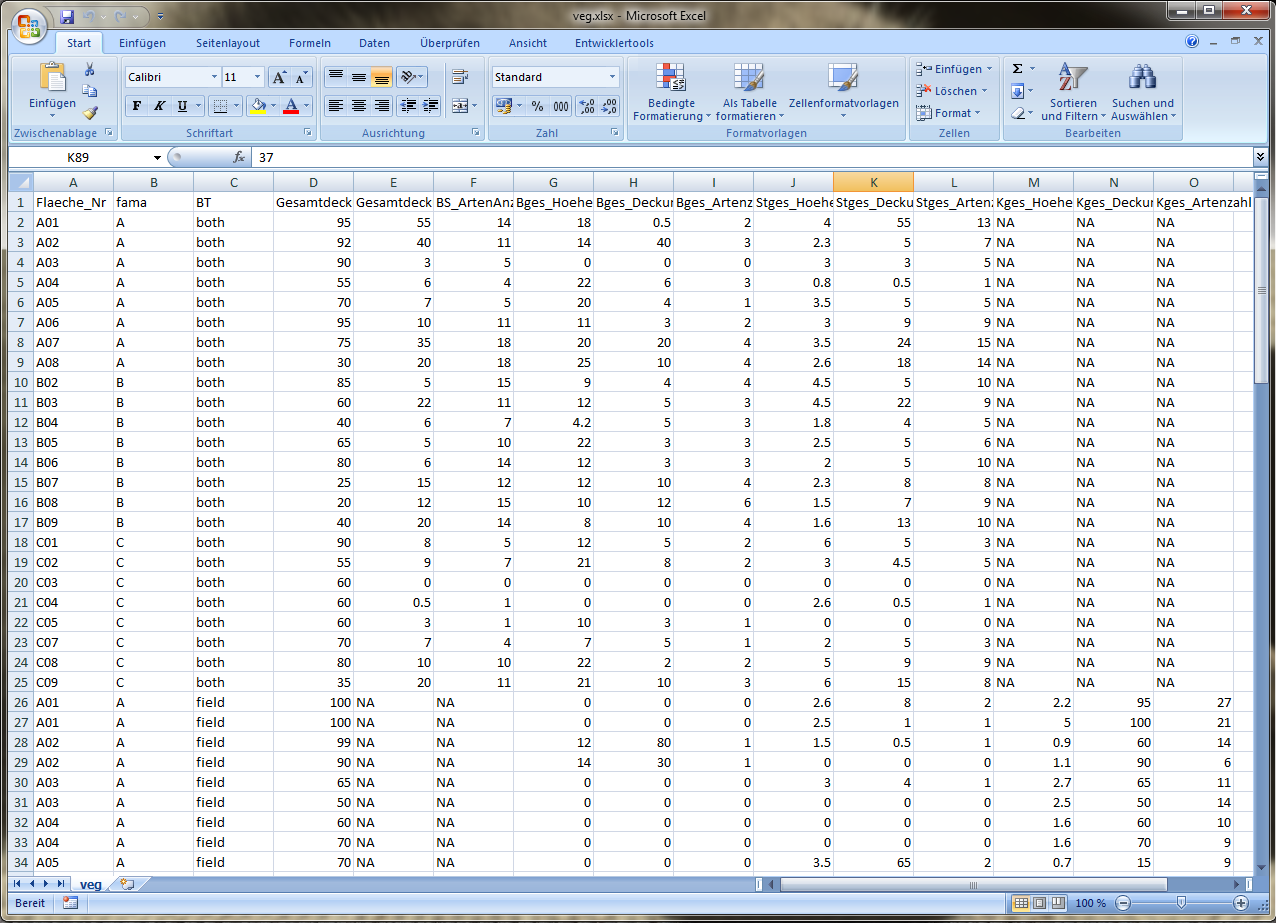
Hier ist eine Excel-Datei, geöffnet in Microsoft Excel, dargestellt. (Du kannst die Ansicht der Bilder bei Bedarf duch die Lupe oben rechts vergrößern!)
csv-Dateien im Detail
Da Comma-Seperated-Values-Dateien hier als best practice vorgestellt werden, wird in der folgenden Slideshow noch einmal auf die Besonderheiten von diesem Dateityp eingegangen. Die Eigenschaften gelten auch für Text-Dateien.
Im Gegensatz zu Excel-Dateien, die über ein vordefiniertes Spaltenformat verfügen, muss bei Comma-Seperated-Values-Dateien immer angegeben werden, mit welchen Trennzeichen die Daten gespeichert wurden.
Da Comma-Seperated-Values-Dateien nicht über ein vordefiniertes Format verfügen müssen folgende Punkte immer mit angegeben werden:
- Spaltenüberschrift (header)
- Spaltentrennzeichen (sep)
- Dezimaltrennzeichen (dec)
-
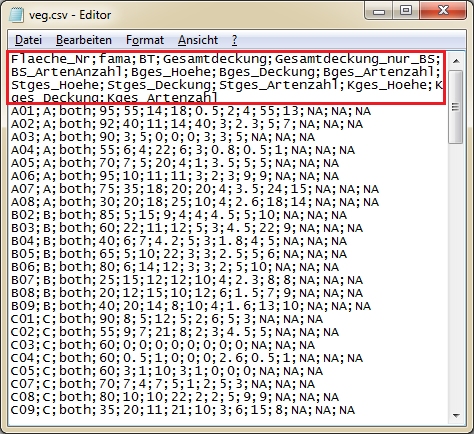
In der ersten Zeile befindet sich die Spaltenüberschriften (Header), hier markiert durch den roten Kasten.
-
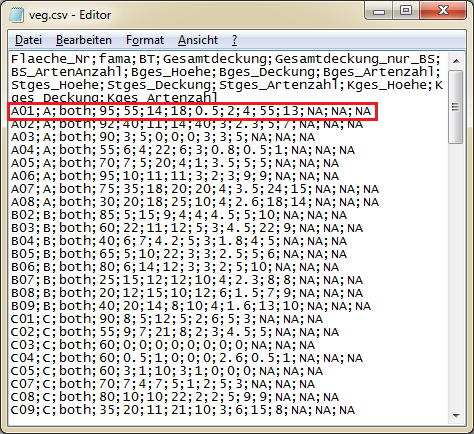
Hier ist die erste Zeile der Datei dargestellt. Die Spalten sind durch ein Trennzeichen (Separator) von einander getrennt werden. In diesem Fall ist das Trennzeichen ein Semikolon.
-
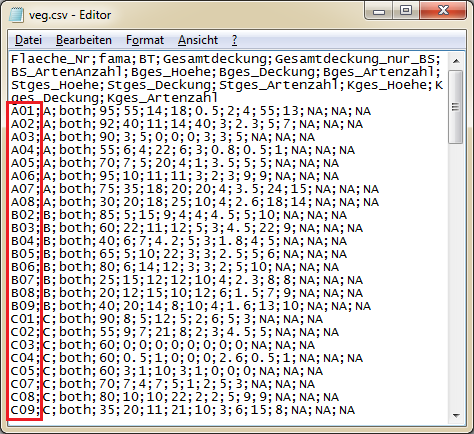
Hier ist die erste Spalte dargestellt, welche von den anderen Spalten durch ein Trennzeichen (Semikolon) getrennt ist.
-
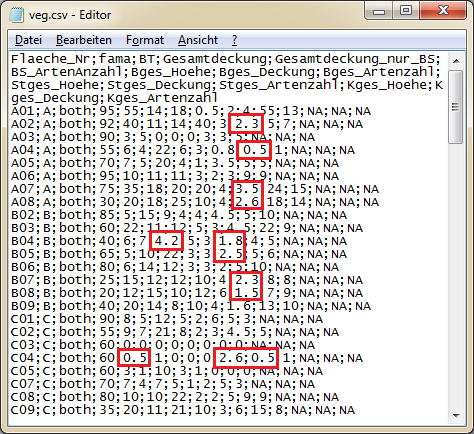
Hier sind einige Werte markiert, die Dezimalzahlen aufweisen. Das Dezimaltrennzeichen kann entweder ein Komma oder wie in diesem Fall ein Punkt sein. (Du kannst die Ansicht der Bilder bei Bedarf duch die Lupe oben rechts vergrößern!)
Vorbereitung der Daten
Bevor es darum geht, wie die Daten in R importiert werden, müssen die Daten vorbereitet werden. Anderenfalls kann es zu verschiedenen Problemen führen: die Daten werden nicht so importiert, wie man es gerne gehabt hätte oder die Daten werden gar nicht importiert.
best practice
-
Grundsätzlich ist die erste Zeile eines Datenblatts immer die Überschrift (Header), während die erste Spalte meist die fortlaufende Nummerierung der Fälle (Stichprobe) darstellt.
-
Namen, Werte und Felder, die Leerzeichen enthalten sollten vermieden werden. Möglicherweise wird sonst jedes Wort als eine eigene Variable erkannt, was zu Fehlern bezüglich der Elemente in einer Zeile im Datenblatt führen kann.
-
Um Wörter voneinander zu trennen, verwende
"."oder"_".Beispiel:
"name1.name2"; "name1_name2" -
Kurze Namen sind immer empfehlenswerter als lange Namen.
-
Eindeutige Spaltenbezeichnungen sind empfehlenswert. Werden mehrere Spalten gleich benannt, so kann es bei Berechnungen zu Fehlern kommen, da keine eindeutige Zuordnung möglich ist.
-
Namen, die folgende Symbole beinhalten sollten vermieden werden:
?, $, %, ^, &, *, (, ), -, #, ?, ,, <, >, /, |, \, [, ], {, und } -
Umlaute sollten vermieden werden, da R kann diese nicht einlesen und kryptische Bezeichnungen entstehen.
-
Kommentare oder Anmerkungen könnten zu extra Spalten führen, die unerwünscht sind.
-
Fehlende Werte sollten mit
NAgekennzeichnet werden (NA = not available).
Arbeitsverzeichnis
Das Arbeitsverzeichnis wird in R als working directory bezeichnet. Es handelt sich hierbei um das Verzeichnis (Ordner), in dem die zu importierenden Dateien gespeichert sind oder gespeichert werden sollen.
Um das Arbeitsverzeichnis zu definieren, wird die Funktion setwd() (set working directory) verwendet. Um das Arbeitsverzeichnis abzufragen wird die Funktion getwd() (get working directory) genutzt.
Innerhalb der Funktion setwd(dir), steht dir für directory. Die directory ist der Pfad zum Arbeitsverzeichnis.
Im folgenden Beispiel ist die das Arbeitsverzeichnis der Ordner "Dateien", der im Ordner "Rlab" auf der Festplatte "C" gespeichert ist.
Bitte beachte, dass die Funktion nur den Vorwärtsschrägstrich / und nicht den von Windows-typischen Rückwärtsschraägstrich \ akzeptiert
setwd("C:/Rlab/Dateien/") # hier wird der Pfad zum Arbeitsverzeichnis angegeben
getwd() # Der Pfad zum Arbeitsverzeichnis wird angezeigt
# Die Funktion hat keine weiteren Argument und so bleiben die Klammern leer
[1] "C:/Rlab/Dateien/"
Wurde das Arbeitsverzeichnis festgelegt, so kann beim Import der Daten auf die Angabe des Pfades verzichtet werden. R kann nun nur auf Dateien zugreifen, die im Arbeitsverzeichnis gespeichert sind.
Bitte beachte, dass immer die Dateiendung der Datei mit angegeben werden muss.
setwd("C:/Rlab/Dateien/")
Funktionsname("Dateiname.Dateiendung") # das können, je nach Funktion, .csv-, .txt-, .xslx- oder .xls-Dateien sein
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Die Funktion read.table()
Bei der Installation von RStudio wird die Funktion read.table() schon mitinstalliert. Die Funktion read.table() ist ein (fast) Alleskönner: Mit ihr kann man so ziemlich jeden Datensatz einlesen. Weitere Funktionen, mit denen Du Daten in R einlesen kannst, werden auf den nächsten Seiten dieses Skriptes vorgestellt.
Tipp: In RStudio unter dem Reiter “Help” findest Du immer die Beschreibungen der einzelnen Packages, bzw. der Funktionen.
Dazu gibst Du einfach in der Suchleiste die Funktionread.table()ein.
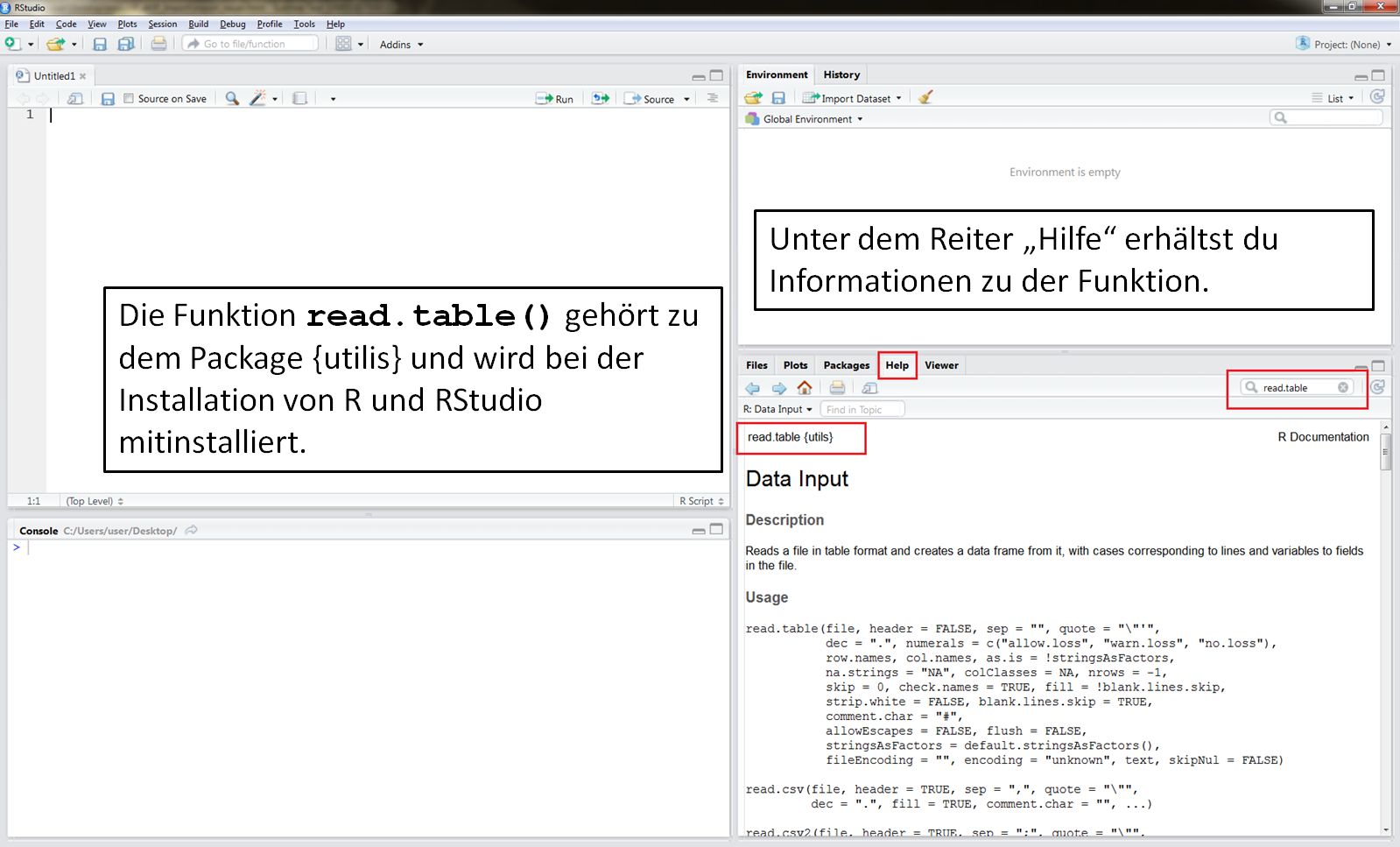
Weitere Informationen zu den Hilfefunktionen findest du im Digitalen Skript zu R-Hilfe in- und außerhalb von R.
Importieren von Comma-Seperated-Values- und Text-Dateien in R
Um .csv- oder .txt-Dateien einzulesen, wird ein und dieselbe Funktion verwendet.
Zunächst musst Du der Funktion read.table() sagen, woher die Daten kommen, die eingelesen werden sollen.
Hier gibt es nun verschiedene Möglichkeiten:
Entweder hast Du schon einen Arbeitsverzeichnis (working directory) festgelegt, dann musst Du nur noch den Dateinamen mit der Dateiendung angeben und kannst auf den Pfad verzichten. Gibt es noch keinen Arbeitsverzeichnis oder Du möchtest keins festlegen, so gibst Du einfach den Pfad mit an:
setwd("C:/Rlab/Dateien/") # Hier wird das Arbeitsverzeichnis festgelegt
read.table("xy.csv") # Die .csv-Datei wird aus dem Arbeitsverzeichnis
# in R nur in der Console importiert.
Oder Du sagst der Funktion jedes Mal erneut, wo die Daten liegen.
Dies funktioniert mit file= "hier-steht-dann-der-Pfad-zu-eurem-Ordner" (z.B. wie oben C:/Rlab/Dateien/).
Bitte beachte, dass am Ende des Pfades immer auch der einzulesende Dateiname mit Dateiendung angegeben werden muss.
daten <- read.table(file = "C:/Rlab/Dateien/xy.csv") # durch die Zuweisung "daten <-"
# wurden die Daten als Objekt in das Environment importiert
# und stehen nun für Funktionen zur Verfügung
Damit bist Du allerdings noch nicht am Ziel, der Import würde nicht korrekt eingelesen werden.
Die Datei würde zwar eingelesen werden, allerdings nicht in dem Tabellenformat, welches du brauchst, um damit rechnen zu können.
Um die Datei richtig einzulesen, musst Du noch weitere Argumente definieren.
- Spaltenüberschrift
header = TRUEoderFALSE- Spaltentrennzeichen
sep = ";"oder","oder " "- Dezimaltrennzeichen
dec = "."oder","
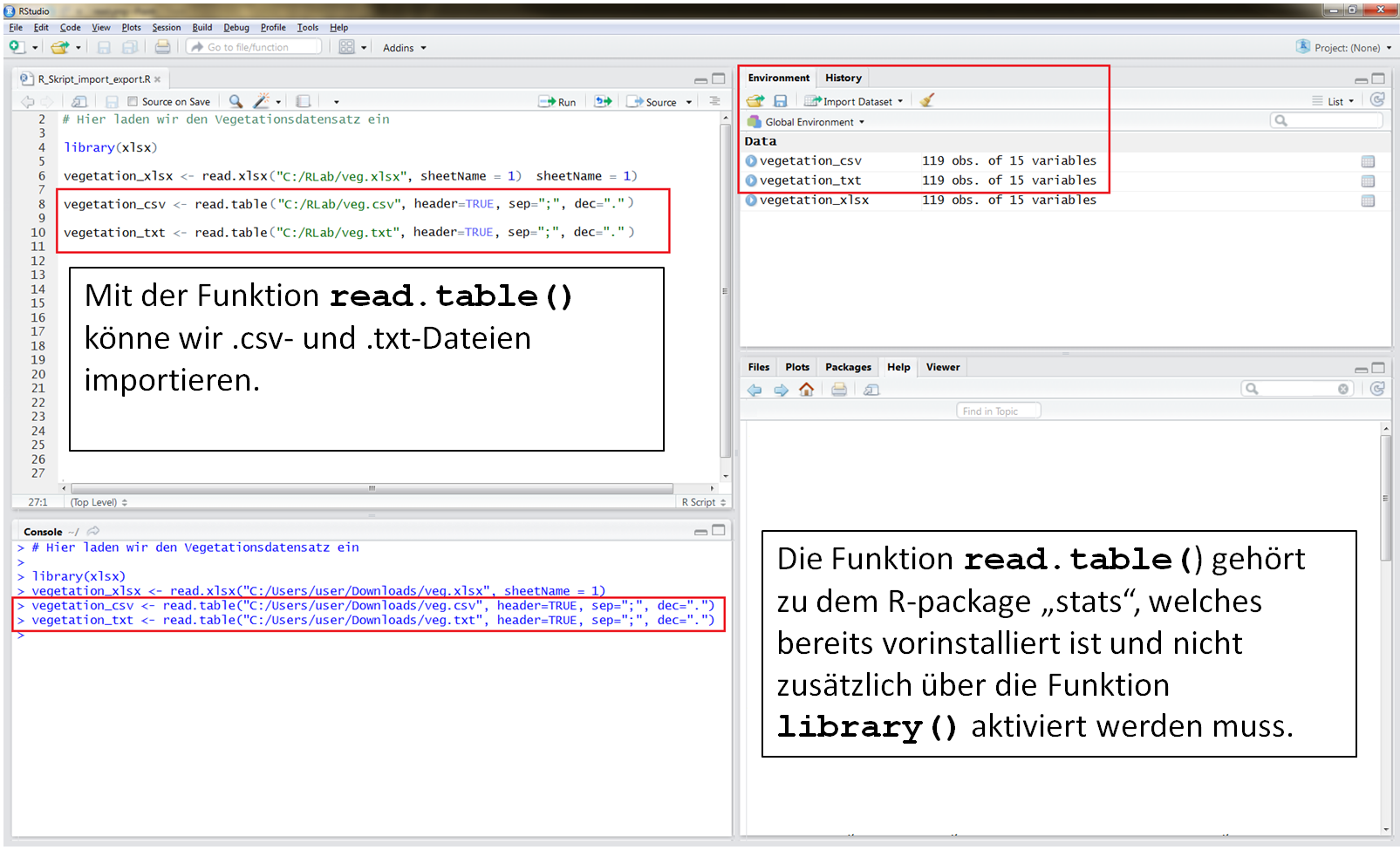
Im folgenden Beispiel sollen die Spaltennamen aus der ersten Zeile gelesen werden header = TRUE , das Spaltentrennzeichen ist ein Semikolon sep = ";" und das Dezimaltrennzeichen ist ein Punkt dec = ".".
daten <- read.table(file = "C:/Users/.../Dateien/xy.csv", header= T, sep=";", dec=".")
Wie das ganze in RStudio aussieht, siehst Du in dieser Abbildung:
Tipp 1: Das Dezimaltrennzeichen bedarf besonderer Aufmerksamkeit. Oftmals ist in Excel ein Komma als Dezimaltrennzeichen eingestellt, die Voreinstellung in R ist aber ein Punkt. Bei falscher Definition wird die Zahl nicht als Zahl erkannt (siehe auch Tipp 3).
Tipp 2: Auch der Spaltentrennzeichen (Separator) ist eine mögliche Fehlerquelle beim Einlesen von Daten: So kann ein falsch definierter Separator dazu führen, dass die Daten nicht richtig in Spalten aufgetrennt werden (alle Werte stehen in einer Spalte).
Tipp 3: Eine einfache Möglichkeit um Fehler zu vermeiden, stellt der Editor dar. Das Programm Editor (oder Notepad) gehört zu jeder Windows-Installation. Im Editor können die Daten in der Formatierung angezeigt werden, in der sie auch abgespeichert sind. So ist ersichtlich welche Dezimaltrennzeichen oder Separator verwendet wurden.
Ein Blick in den Editor lohnt sich immer.
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Comma-Seperated-Values-Dateien als ,,best practice"
Warum sollte ich meine Daten im Comma-Seperated-Values-Format speichern?
Gibt es das perfekte Datenformat?
Nein, natürlich nicht. Aber es gibt eines, welches ganz nah dran ist: das gute, alte Comma-Separated-Value-Format (.csv).
Im Folgenden werden einige Vorteile vom .csv-Dateiformat aufgelistet.
1. Das .csv Dateiformat ist nicht urheberrechtlich geschützt.Das .csv-Dateiformat gibt es seit Jahrzehnten und niemandem gehört das Format. Du brauchst dir also keine Sorgen zu machen, dass du für das Format bezahlen musst oder das du eine spezielle Software brauchst, um das Format lesen oder schreiben zu können.
2. Alle gängigen Dateiverarbeitungsprogramme unterstützen das Format, u.a. R, Excel, Windows Editor und auch Macintosh Betriebssysteme.Auf die Besonderheiten des .csv Exports aus R und Import in Excel wird im Skript zu Export von Daten aus R. eingegangen.
3. Der Umgang mit .csv-Dateien ist einfach.Oftmals werden die Daten nicht im gewünschten Format von Anderen oder von Websites zur Verfügung gestellt. Das .csv-Dateiformat stellt hier einen einfachen und unkomplizierten Weg des Datentransfers dar.
4. .csv-Dateien sind im Tabellenformat aufgebaut.Eine .csv-Datei ist wie eine Tabelle aufgebaut, dadurch ist eine schnelle Bearbeitung und Konvertierung möglich.
5. Eine .csv-Datei ist einfach zu analysieren.Da für .csv-Dateien keine formale Spezifikation besteht, kann jede Software .csv-Dateien analysieren.
Zusammenfassend kann man sagen, dass das .csv Dateiformat zwar nicht perfekt ist, aber die Vorteile (gerade im Bezug auf R) überwiegen. Deshalb empfehlen wir das .csv Dateiformat als best practice!
Den Originalartikel vom DataMarket Blog findet ihr hier .
Importieren von Excel-Dateien in R
Es gibt verschiedene Möglichkeiten Daten aus Excel in R zu importieren.
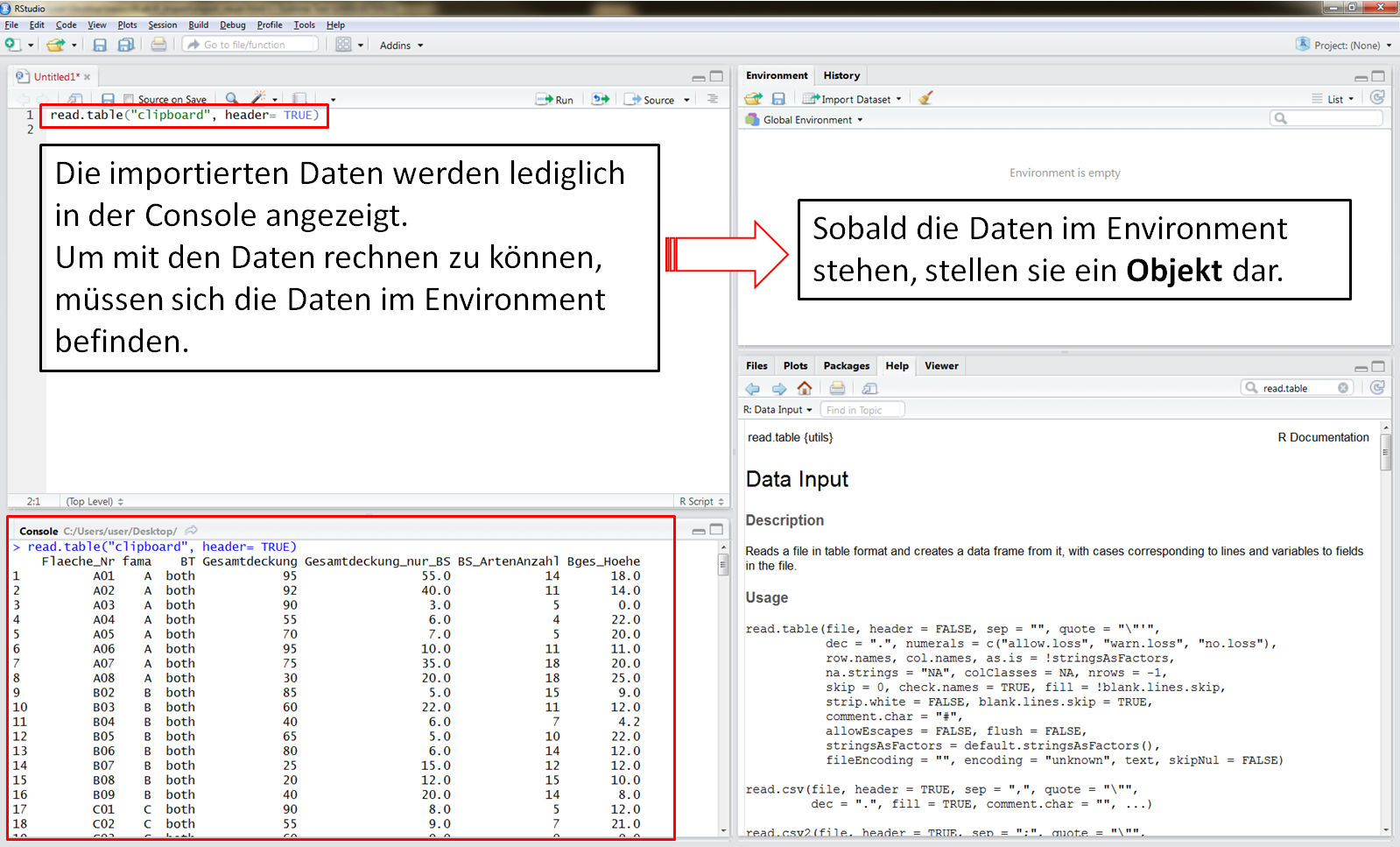
Die einfachste Möglichkeit ist es, die Daten aus Excel zu kopieren und in R einzufügen (copy and paste). Dafür muss man lediglich das Excelblatt geöffnet haben, die Daten kopieren und über das clipboard in R einfügen. Die Daten werden hier aus der Zwischenablage in R eingefügt. Das zusätzliche Argument header= TRUE ermöglicht, dass die Variablennamen aus der ersten Zeile der Tabelle gelesen werden.
> read.table("clipboard", header=TRUE) # Die Spaltenbezeinungen werden aus der ersten Zeile gelesen
Nun wird die kopierte Tabelle in der Console ausgegeben.
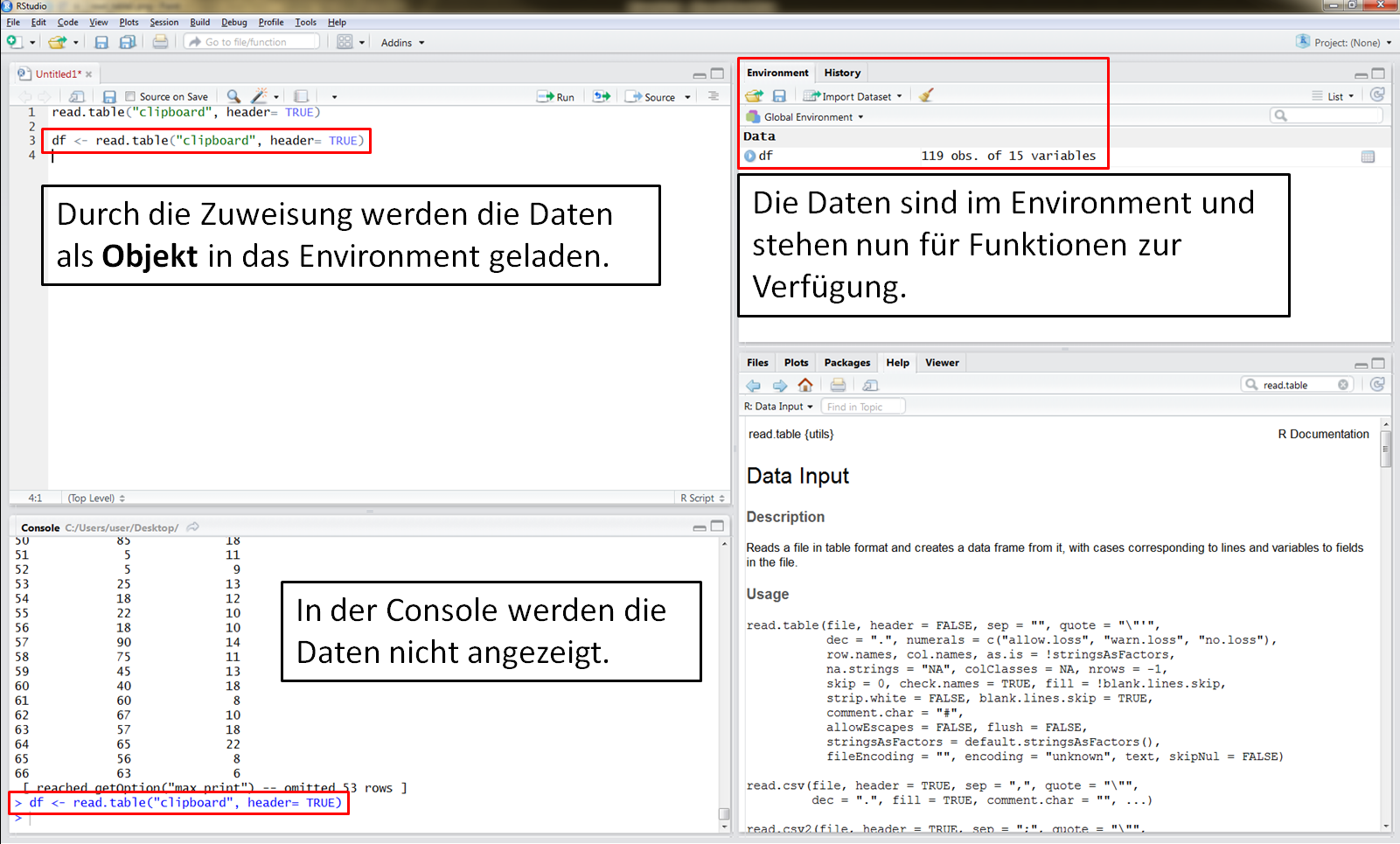
Durch die Zuweisung wird die kopierte Tabelle als Objekt im Environment in R angezeigt. Funktionen können nur auf Objekte zugreifen, die Daten müssen also im Environment stehen, damit mit ihnen gerechnet werden kann.
Um abgespeicherte Excel-Dateien in R zu importieren brauchst Du ein Package: xlsx.
Dieses musst Du zunächst mit der Funktion install.packages()installieren und dann mit der Funktion library() aktivieren.
Mit der Funktion read.xlsx() kannst Du problemlos die abgespeicherte Dateien mit den Endungen .xlsx oder .xls in R importieren.
install.packages("xslx", dependencies=T) # Package installieren
# mit dependencies=T werden alle weiteren benötigten Packages gleich mitinstalliert
library(xlsx) # Package aus der Library laden
# das Package kann nun verwendet werden
In dem folgenden Codebeispiel wurde die zu importierende Excel-Datei gleich einem Objekt ("Tabelle") zugewiesen.
Es wurde vorher kein Arbeitsverzeichnis definiert, sodass der gesamte Pfad zu den Excel-Datei mit angegeben werden musste.
In diesem Fall wird das erste Arbeitsblatt der Excel-Datei importiert.
Es befindet sich nun die "Tabelle" als "Data" im RStudio Environment.
Tabelle <- read.xlsx(file = "C:/Rlab/Dateien/xy.xlsx", sheetName= "Mappe1") # Daten importieren
Wie das ganze in RStudio aussieht, siehst Du in dieser Abbildung:
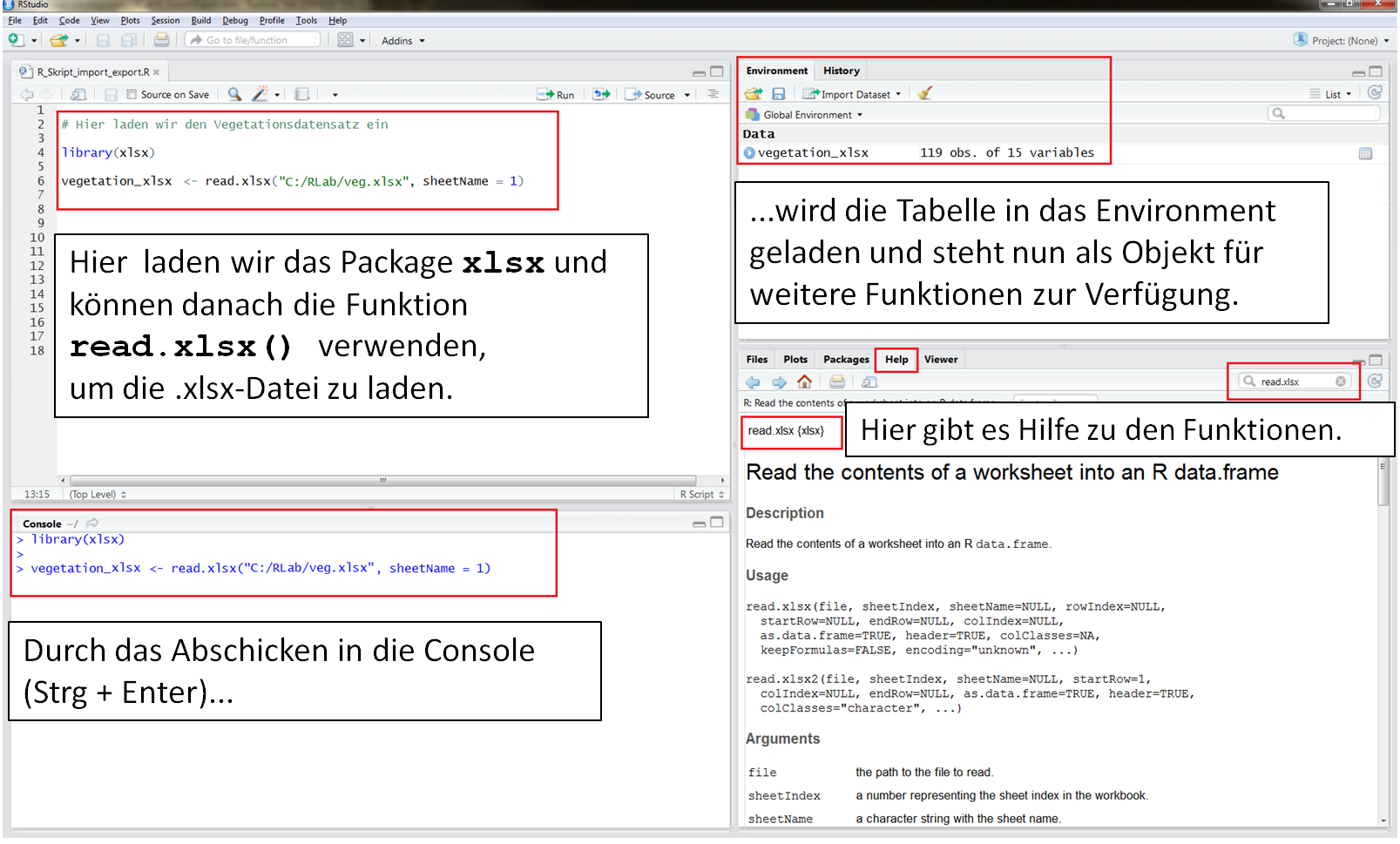
Tipp: Welche Zahlenformate die einzelnen Spalten der Tabelle in R haben erfährst Du im Digitalen Skript zu den Skalenniveaus.
Welche verschiedenen Formate es von eingelesenen Daten in R gibt erfährst Du im Digitalen Skript zu Zahlen- und Datenformaten in R.
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Wurden meine Daten korrekt in R importiert?
Um zu überprüfen, ob die Daten richtig in R importiert wurden gibt es folgende nützliche Funktionen.
str() # Hiermit wird die Struktur der Tabelle angezeigt;
die ersten 10 Werte jeder Variable und Info über die Menge der Daten werden ausgegeben.
head() # Die ersten 6 Spalten und Zeilen werden angezeigt
tail() # Die letzten 6 Spalten und Zeilen werden angezeigt
dim() # Hiermit werden die Anzahl der Zeilen und der Spalten angezeigt
View() # Achtung Case Sensitivity! View nicht view
Weitere Informationen findest Du im Digitalen Skript zu Zahlenformaten und Datenformaten in R.
Zusammenfasung
In diesem Kapitel wurden Dir die drei wichtigsten Dateitypen vorgestellt. Dir wurden Hinweise für die Vorbereitung der Daten gegeben, damit sie dann richtig in R importiert werden können. Desweiteren hast Du Funktionen kennengelernt, mit denen Du überprüfen kannst, ob die Dateien richtig in R eingelesen wurden.
Wie Du Daten aus R exportieren kannst, erfährst Du im Digitalen Skript zum Export von Daten aus R.
Klappt etwas nicht wie gewünscht?
Schreibe Deine Frage als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Dir gefällt RLab?
Nimm dir ein R!
Alles ist besser mit einem R!