Zahlenformate und Datenformate in R

Maria Bobrowski
RLab - Skriptbasierte modulare Umweltstatistik (Universitätskolleg 2.0)
Universität Hamburg
RLab-Impressum
Gefördert im Rahmen des „Lehrlabors“ im Universitätskolleg 2.0 aus Mitteln des BMBF (01PL17033)

Dieses Digitale Skript von Maria Bobrowski, Universitätskolleg 2.0 / Lehrlabor, Universität Hamburg, ist lizenziert unter einer Creative Commons Namensnennung - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz.
elearn.js Template
Universität Hamburg
Das elearn.js Template von Universität Hamburg ist lizenziert unter einer Creative Commons Namensnennung - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz
Zahlenformate und Datenformate in R
Maria Bobrowski
RLab - Skriptbasierte modulare Umweltstatistik (Universitätskolleg 2.0)
Universität Hamburg
CC BY-SA 4.0| 2017
Ziel
In diesem Skript erfährst Du, wie die Skalenniveaus in R bezeichnet werden.
Die Skalenniveaus werden in R durch verschiedene Zahlenformate repräsentiert.
Diese Zahlenformate bilden die Grundlage für die verschiedenen Datenformate.
Die Datenformate wiederum werden in R als Objekt bezeichnet.
Am Ende wird Dir gezeigt wie Du die Zahlenformate und Datenformate ansteuern und nutzen kannst.
Dabei werden Dir Hinweise zum Umgang gegeben:
Zum Beispiel wie Du überprüfen kannst, ob die Daten korrekt in R eingelesen wurden.
Voraussetzungen
Um dieses Skript zu verstehen, solltest Du
- das Digitale Skript Import von Daten in R und
- das Digitale Skript zu den Skalenniveaus bearbeitet haben.
Das ist alles in Import von Daten in R und Skalenniveaus beschrieben, schaue gegebenenfalls dort nach und kehre dann hierher zurück!
Gut ist, wenn Du R und RStudio installiert hast, damit Du die hier dargestellten Beispiele selbst in R ausprobieren und so am besten nachvollziehen kannst.
Für Anregungen und Kommentare zur Verbesserung ist das RLab-Team immer dankbar! Du kannst auch Fragen zu den Inhalten stellen! Nutze für all das gerne die Kommentar-Funktion!
Überblick
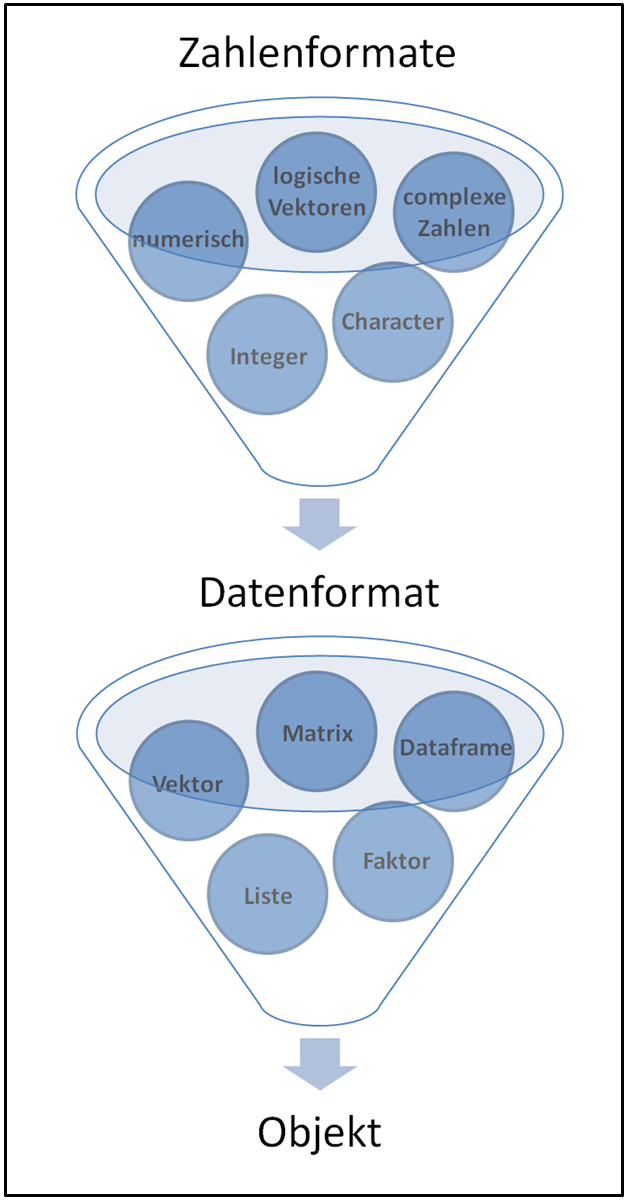
Die folgende Grafik gibt einen Überblick über die Hierachie von Zahlenformaten, Datenformaten und Objekten in R.
Die Zahlenformate bestehen aus 5 atomaren Grundklassen: numerische Zahlen, Integer, complexe Zahlen, logische Vektoren und Character.
Die Zahlenformate bilden die Grundlage der Datenformate: Vektor, Faktor, Matrix, Liste oder Dataframe.
Ein Datenformat stellt in R ein Objekt dar.
Auf den folgenden Seiten werden Zahlenformate, Datenformate und Objekte genauer beschrieben.
Skalenniveaus und Zahlenformate in R
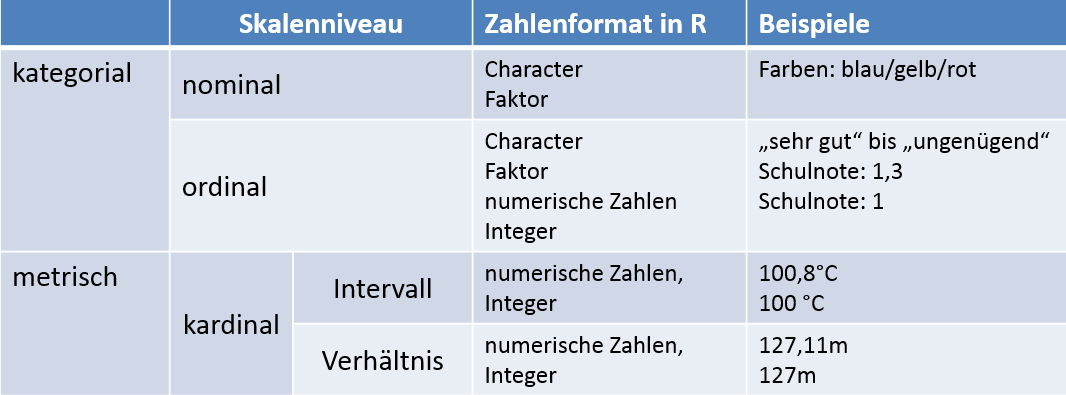
Nachdem Du nun gelernt hast, dass eine Zahl nicht gleich eine Zahl ist, ist es Zeit sich die Skalenniveaus in R anzuschauen.
Skalenniveaus werden in R durch verschiedene Zahlenformate repräsentiert.
Die folgende Tabelle zeigt die Skalenniveaus mit den entsprechenden Zahlenformaten in R.
Die Tabelle zeigt, dass für die verschiedenen Skalenniveaus mehrere Zahlenformate in R zur Verfügung stehen.
Zahlenformate in R
Zunächst einmal gibt es 5 atomare Grundklassen (auch basic atomic classes genannt), diese stellen die Zahlenformate in R dar.
1. Numerische Zahlen (zum Beispiel: 2, 2.0, pi)
Numerische Zahlen können ganze oder Dezimalzahlen sein.
2. Integer (zum Beispiel: 2L, 3L, 4L, 5L)
Bei Integern handelt es sich um ganze Zahlen. In der Mathematik und Informatik wird zwischen Dezimalzahlen und ganzen Zahlen unterschieden. Dennoch speichert R alle Zahlen als Dezimalzahlen ab, auch wenn sie keine Nachkommastelle aufweisen. Möchte man eine Zahl als Integer ausgeben, so wird die Zuweisung "L" angehängt. Wird aber ein Integer mit einer Dezimalzahl zum Beispiel multipliziert, so wird das Zahlenformat in numerisch automatisch geändert.
x = 7L # explizit als Integer zugewiesen
y = 0.11 # numerisches Zahlenformat
z = x*y # Multiplikation von Integer mit numerischem Zahlenformat
z
[1] 0.77 # Ergebnis der Multiplikation
str(z) # Welches Zahlenformat hat z?
num [1] 0.77 # Das Ergebnis ist numerisch
3. Complexe Zahlen
Complexe Zahlen können Ausdrücke wie 1 +0i oder 1 + 4i sein.
4. Logische Vektoren
Der Datentyp logic besitzt die Werte TRUE und FALSE.
1 < 2
[1] TRUE
1 == 1 & 2 >= 3
[1] FALSE
Mit logischen Vektoren kann auch gerechnet werden, wobei TRUE als 1
und FALSE als 0 interpretiert wird.
TRUE + FALSE
[1] 1
(1 == 1) + (2 >= 3)
[1] 1
Logische Vektoren spielen eine wichtige Rolle bei der Ablaufsteuerung und bei der Indizierung von Datenstrukturen!
5. Character (zum Beispiel: "A", "B", "Names", "Meinnameist")
Das Format Character kann entweder aus einzelnen Buchstaben oder ganzen Wörtern bestehen.
Im Allgemeinen stellt dieses Formate Text dar.
6. Faktoren (Vektor aus Integers mit Character-Werten)
Bei Faktoren handelt es sich um einen Zahlenformat, allerdings ergeben Faktoren nur in Kombination mit Vektoren einen Sinn. Du findest die weiteren Ausführungen bei Faktoren.
Datenformate in R
Nachdem Du die Zahlenformate kennengelernt hast, werden nun die Datenformate vorgestellt.
Die wichtigsten Datenformate in R sind:
- Vektor
- Faktor
- Matrix
- Liste
- Dataframe
Im Folgenden Abschnitt soll genauer auf Vektor-, Faktor-, Matrix-, Listen und Dataframe-Datenformate eingegangen werden.
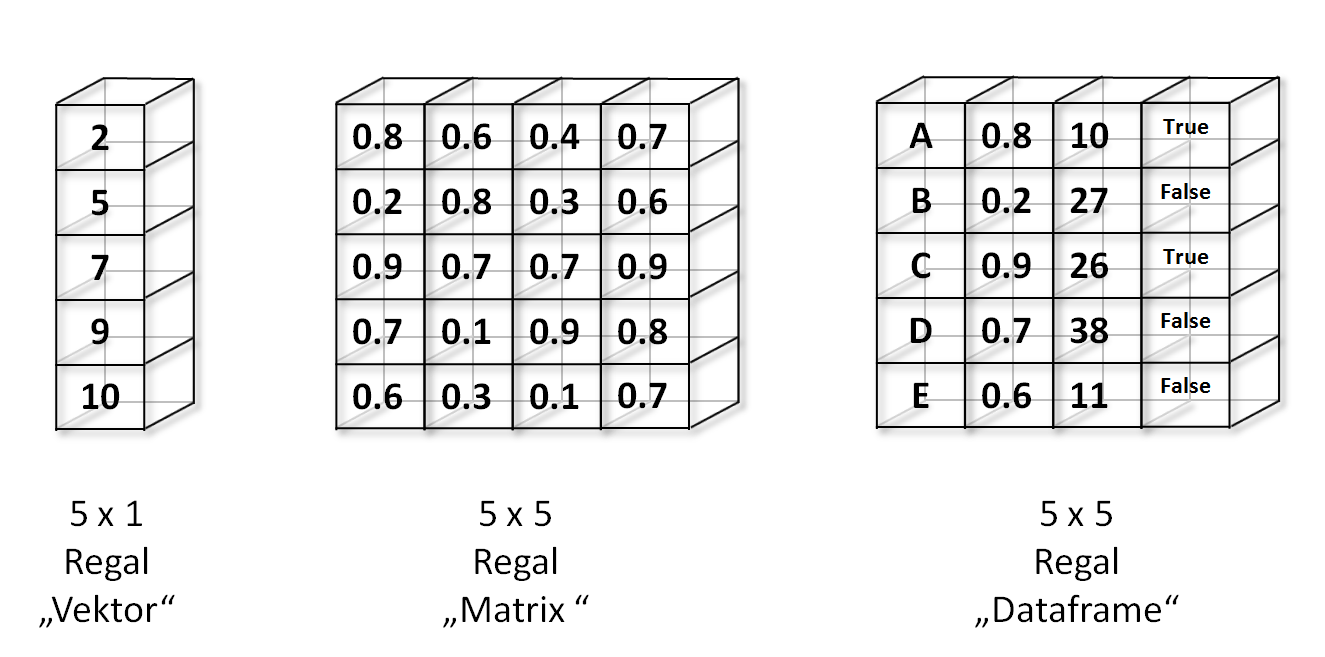
Die Veranschaulichung der Datenformate in R wird hier anhand von Regalen dargestellt.
Je nachdem, welche Zahlenformate zusammen in einer Tabelle/Regal stehen, ergibt sich daraus das Datenformat.
Kommen ausschließlich gleiche Zahlenformate vor, so handelt es sich, je nach Dimension (Anzahl der Spalten), entweder um einen Vektoren oder eine Matrix.
Beispielsweise wird hier der Vektor ausschließlich durch Integer und die Matrix ausschließlich durch numerische Werte repräsentiert.
Kommen unterschiedliche Zahlenformate in einem Datenformat vor, so handelt es sich um einen Dataframe, der in diesem Beispiel durch Character, numerische Zahlen, Integer und logische Vektoren gebildet wird.
Vektor
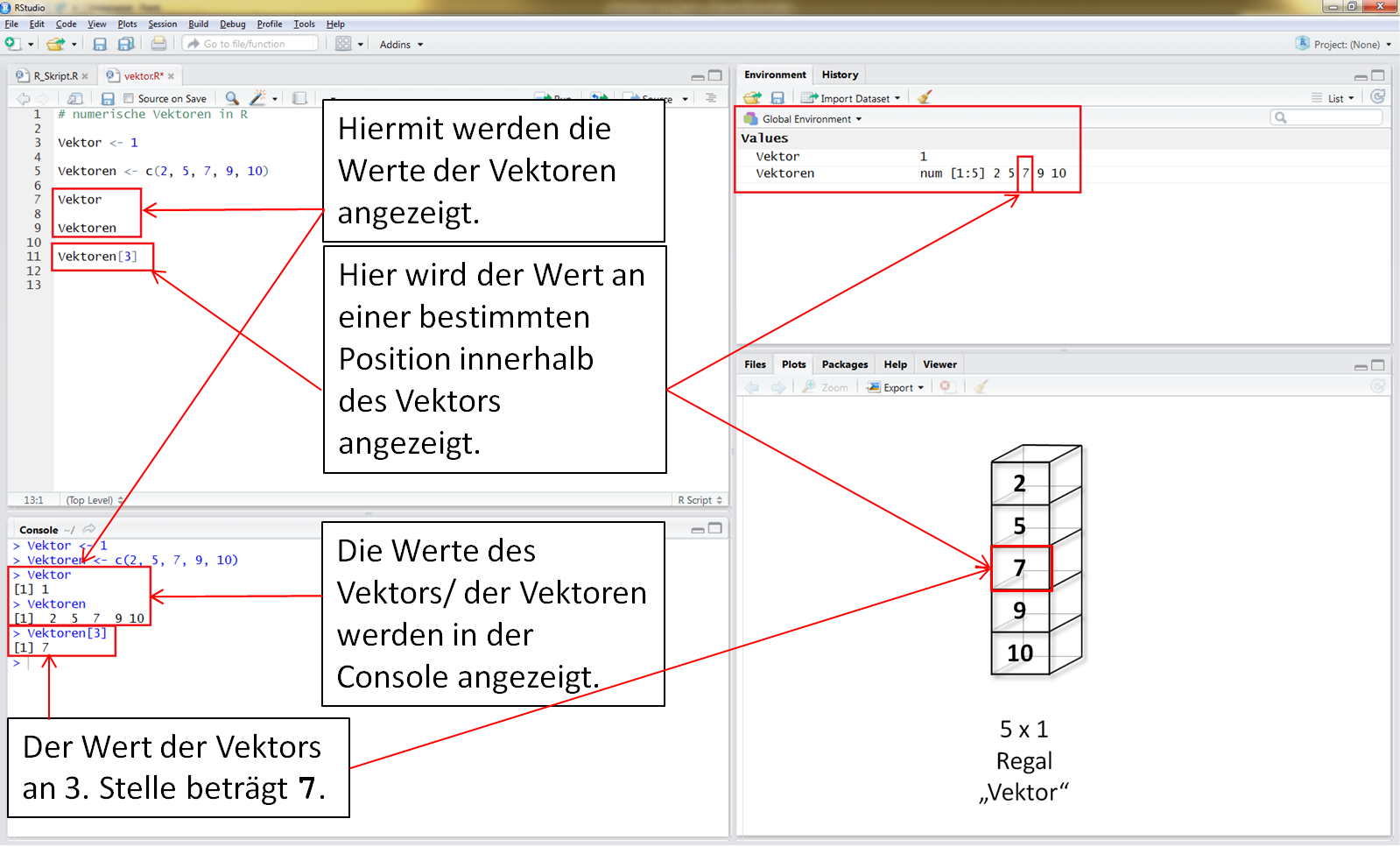
Oftmals hat man es mit einer Stichprobe zu tun. Diese lassen sich gut in Form eines Vektors abbilden.
Wurde zum Beispiel die Höhe von Bäumen in einem Gebiet gemessen, so lassen sich diese Werte als Vektor "l" (Länge) abspeichern. Ein solcher Vektor ist nichts anderes als eine Aneinanderreihung von einzelnen Messwerten, wobei über eine fortlaufende Nummerierung festgehalten wurde, welcher Wert zu welchem Baum gehört.
Die folgende Slideshow gibt einen Überblick über numerische und nicht-numerische Vektoren.
-

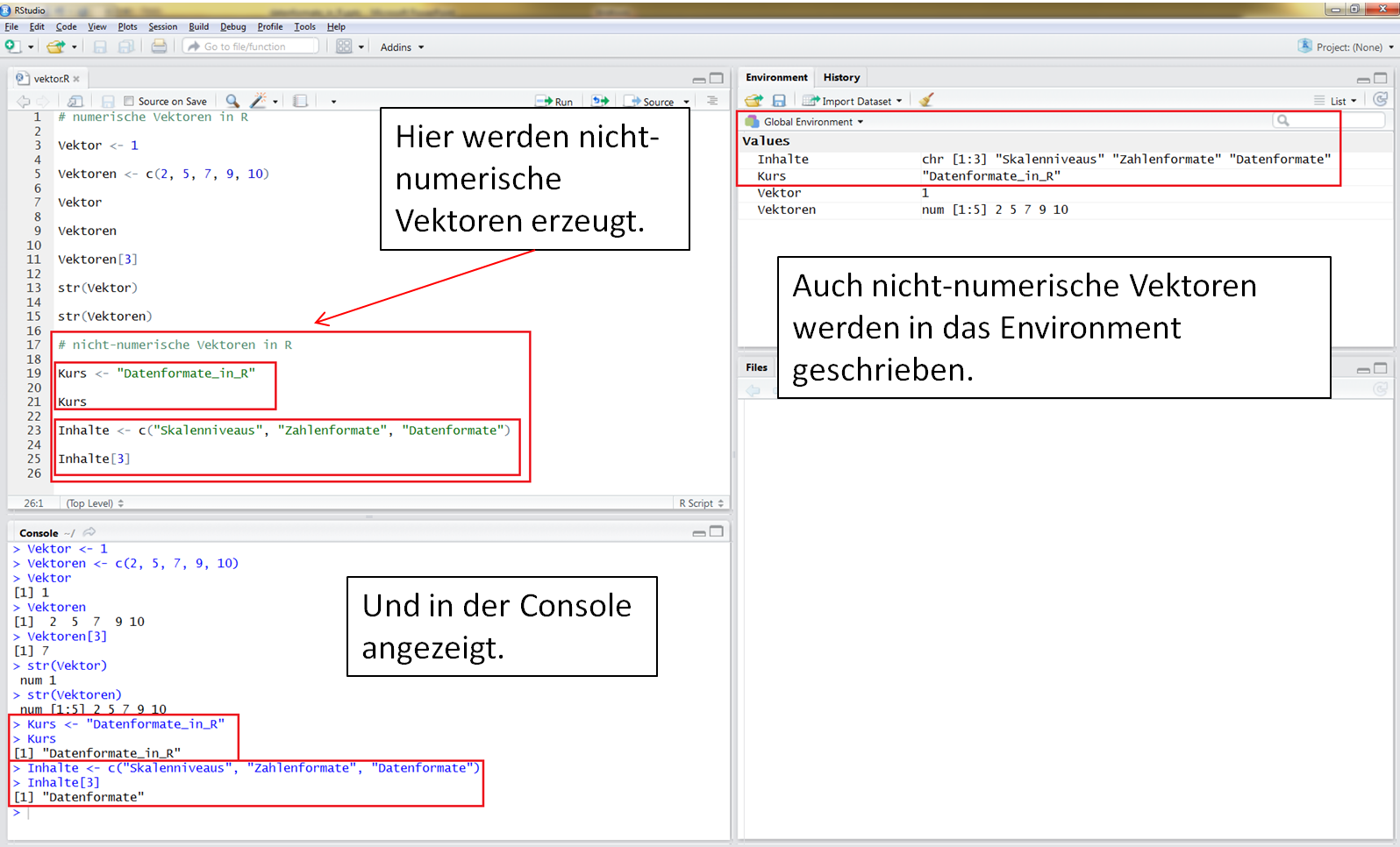
Vektoren werdem als "Values" in das Environment geschrieben.
-
-
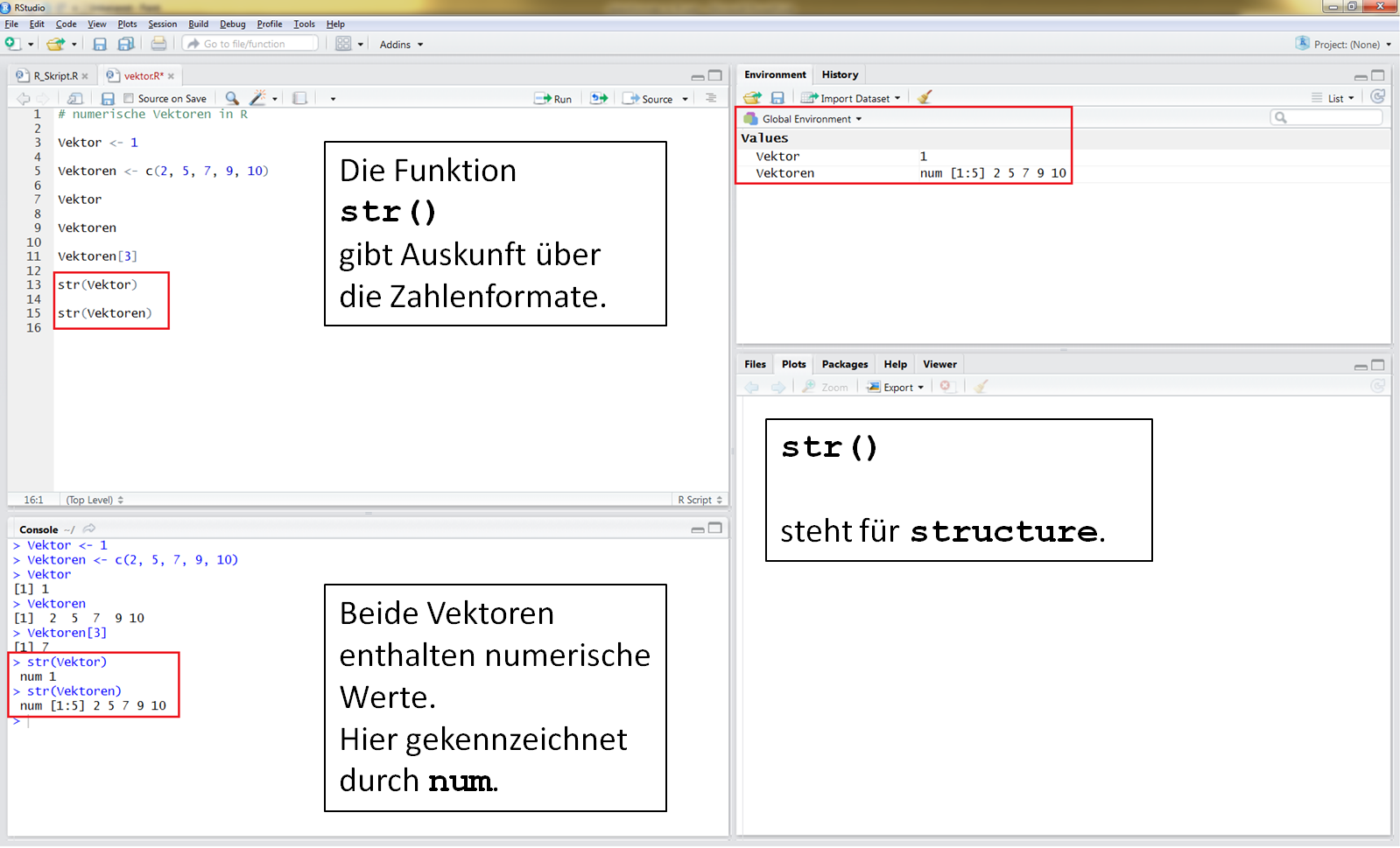
Mit der Funktion str() kannst Du Dir die Zahlenformate in Datenformaten anzeigen lassen. Hier handelt es sich um numerische Werte (Zahlenformat) in einem Vektor (Datenformat).
-
-
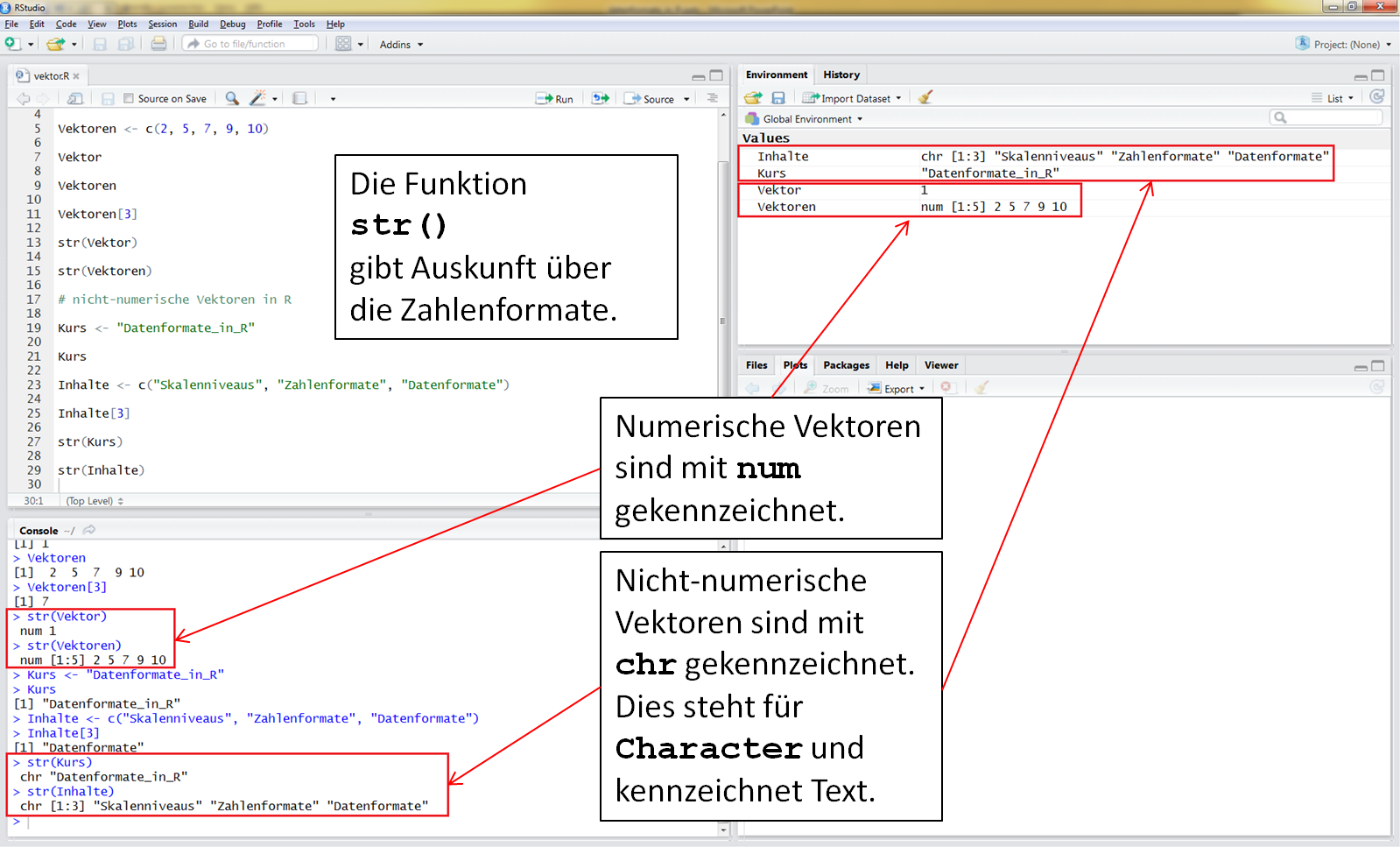
Grundsätzlich ist ein Vektor eine geordnete Sammlung gleicher Zahlenformate. Werden Zahlenformate gemischt, so erhält der Vektor den „Obertypen“ seiner Einträge, also bei "characters und anderen Zahlenformat" das Zahlenformat "character", bei "numerisch und logischen Vektoren" das "numerische Zahlenformat".
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Faktor
Bei einem Faktor handelt es sich um einen Zahlentyp, der aber nur in Kombination mit Vektoren einen Sinn ergibt und deshalb als Datentyp behandelt wird.
Das Format Faktor besteht aus nominalskalierten und ordinalskalierten Daten. Die nominalen Werte sind die levels ohne Ordnungsrelation (zum Beispiel Farben oder Pflanzenarten). Die ordinalskalierten Daten hingegen sind die levels mit Ordnungsrelation (zum Beispiel Schulnoten, Alter oder Höhe). Die levels eines Faktors werden in R durch numerische, ganzzahlige Werte mode von 1 bis k codiert.
Faktoren werden mit der Funktion factor() erzeugt. Im folgenden Beispiel wird zunächst ein Vektor mit Character-Werten erstellt, der dann in einen Faktor umgewandelt wird.
> data_character <- c("x","z","y","z","x","x","y") # Character-Werte
> data_factor <- factor(data_character) # Umwandlung in einen Faktor
In der Ausgabe wird deutlich, dass bei dem Faktor keine Anführungszeichen gesetzt werden. Dafür erscheinen hier die "Auspägungen", die levels :
> data_character # Character-Vektor
[1] "x" "z" "y" "z" "x" "x" "y"
> data_factor # Faktor
[1] x z y z x x y
Levels: x y z
Der grundlegende Unterschied zwischen Character-Vektoren und Faktoren liegt in der Verwaltung der beiden. Bei einem Faktor werden die Ausprägungen sortiert, Dupletten entfernt und durchnummeriert. Bei dem Faktor erhält x die interne Codierung von 1, y die interne Codierung von 2 und z die interne Codierung von 3. Diese Zahlen sind die levels des Faktors. Jedem level ist ein label zugeordnet, welches den Text der ursprünglichen Zuweisung enthält.
Unterschied zwischen
levelsundlabels
Bei der Ausgabe von Faktoren in der Console werden dielabelsangezeigt, aber alslevelsbezeichnet.
In der folgenden Übersicht werden Dir die Unterschiede zwischen levels und labels gezeigt.

levels, welche die Anzahl der Faktoren enthalten und zum anderen die class, welche angibt, ob es sich um einen ungeordneten Faktor factor oder einen geordneten Faktor ordered handelt.
> data = factor(c(1,3,2,3,1,1,2), levels = c(1,2,3), labels = c("x", "y", "z"))
> data
[1] x z y z x x y
Levels: x y z
> levels(data)
[1] "x" "y" "z"
> class(data)
[1] "factor"
> factor(data) # ungeordnet
[1] x z y z x x y
Levels: x y z
> ordered(data) # geordnet
[1] x z y z x x y
Levels: x < y < z
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Matrix
Matrizen sind mehr-dimensionale Vektoren. Ansonsten verhalten sie sich wie alle Vektoren und enthalten nur ein Zahlenformat.
Die folgende Slideshow gibt einen Überblick über Matrizen.
-
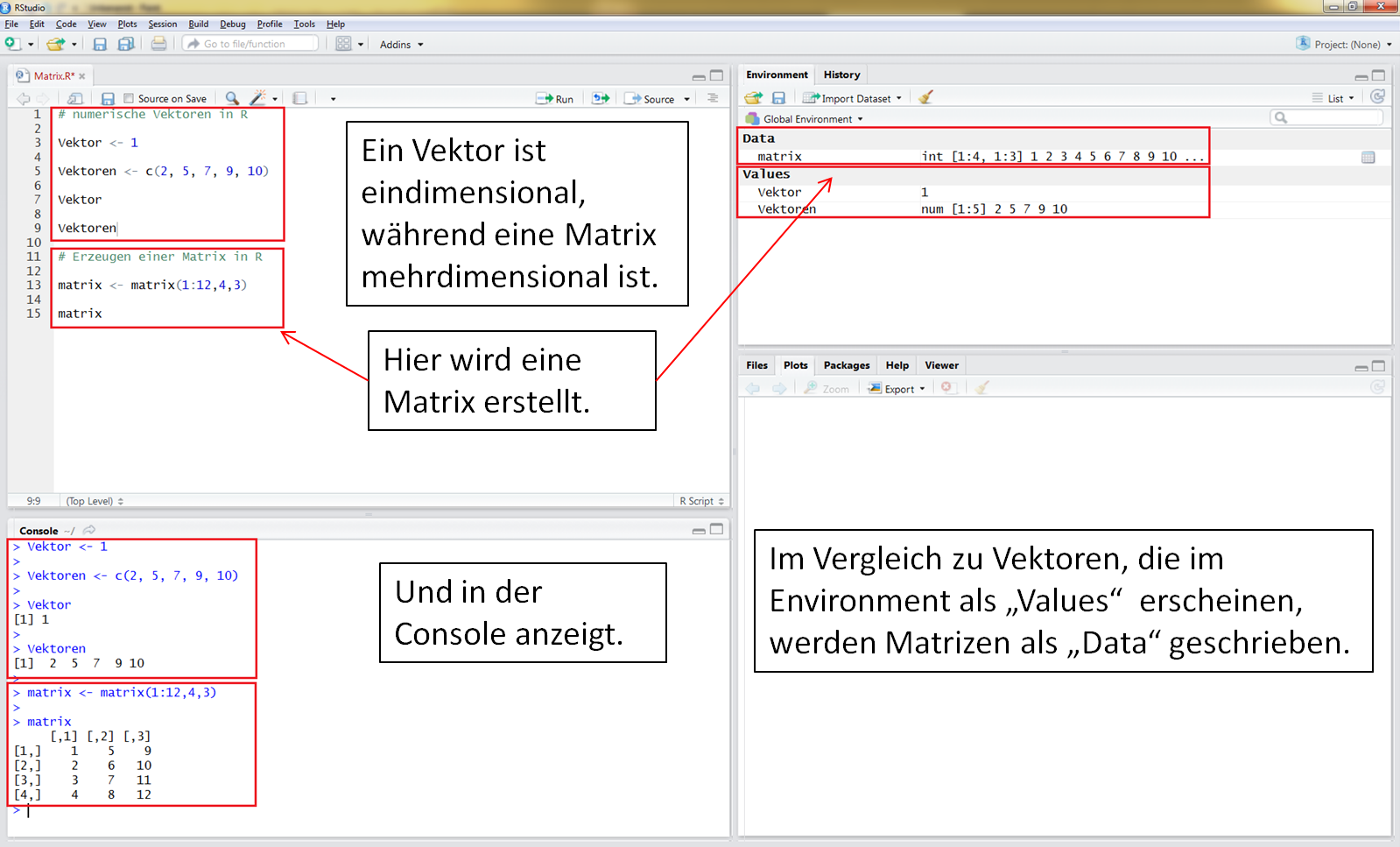
Da Matrizen im Vergleich zu Vektoren mehr als eine Dimension besitzen, werden sie als "Data" in das Environment geschrieben. Eindimensionale Vektoren werdes als "Values" geschrieben.
-
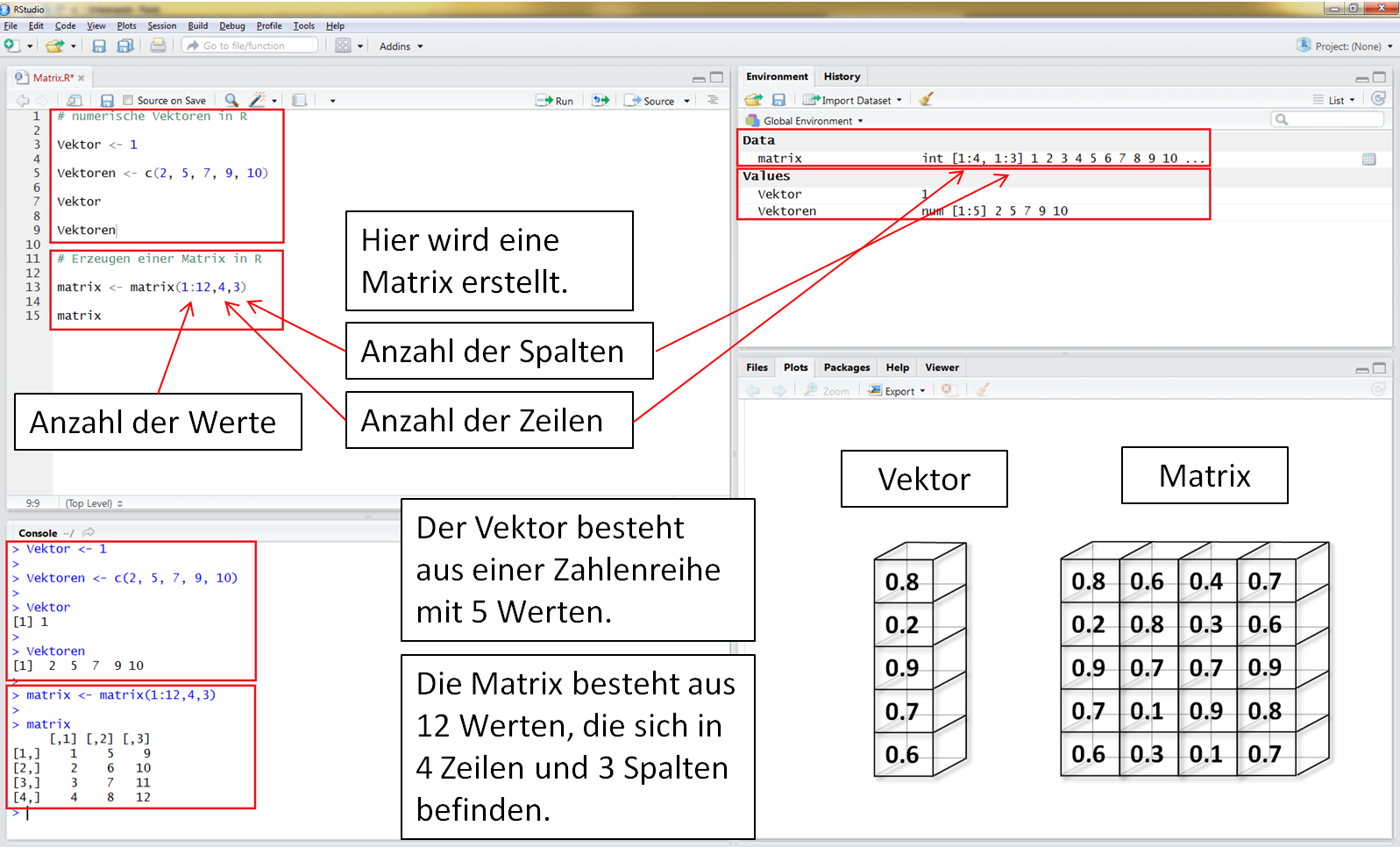
Das Zahlenformat des Vektors ist "numerisch", das Zahlenformat der Matrix ist als "Integer" (ganze Zahlen) gekennzeichnet. Innerhalb von Vektoren und Matrizen kann es nur ein Zahlenformat geben. In diesem Beispiel sind alle Werte numerisch (Vektor) oder Integer (Matrix).
-
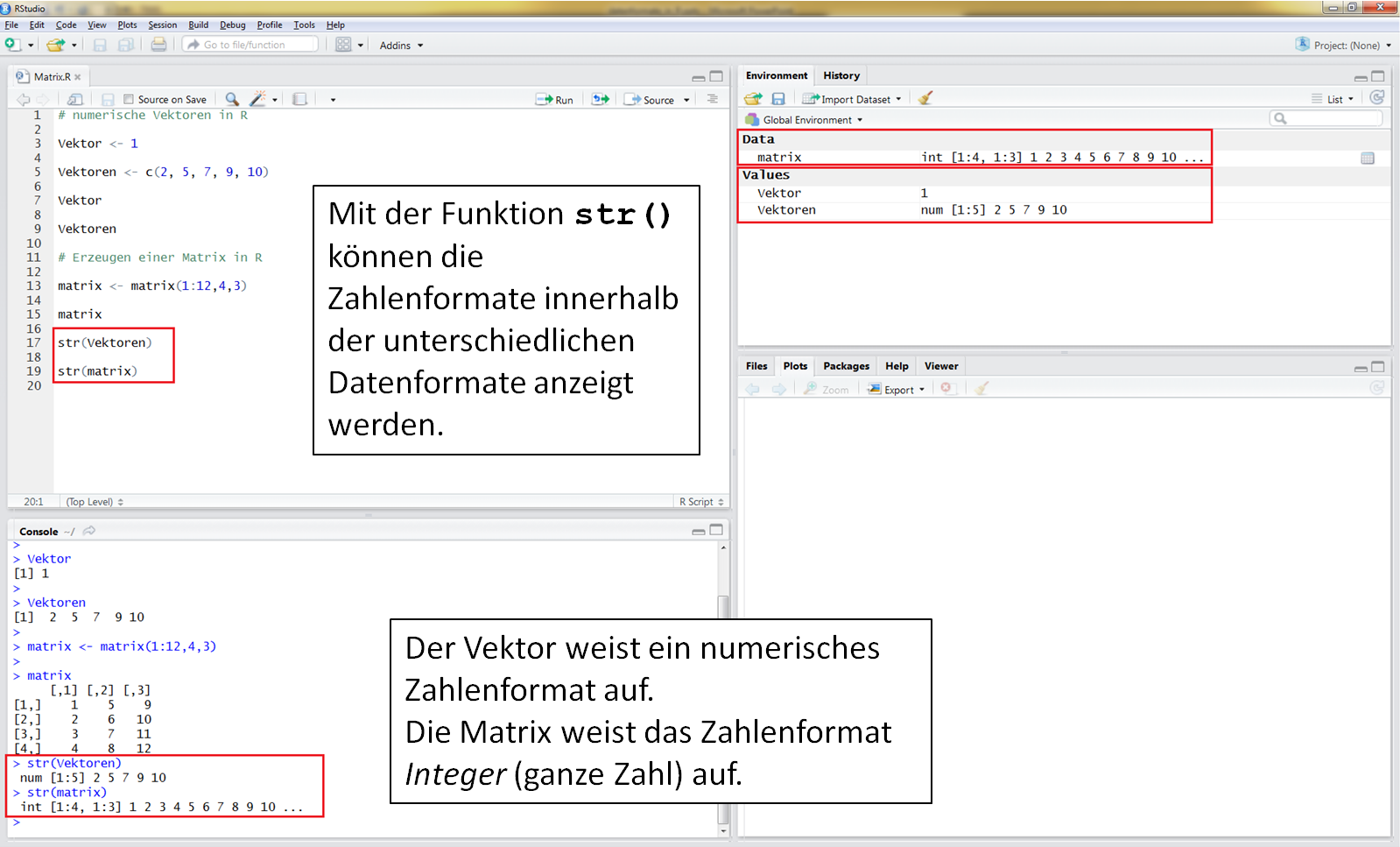
Die Funktion str() gibt Auskunft über Zahlenformate, Datenformate und die ersten 10 Werte. In diesem Fall handelt es sich um numerische Werte im Vektor und um Integer Werte in der Matrix
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Listen
Eine Liste ist eine Sammlung von beliebigen Zahlenformaten, beliebigen Datenformaten und beliebiger Größe. So können Listen sind aus verschiedenen Elementen aufgebaut sein, die numerische, logische oder Character Zahlenformate enthalten. Sowohl Vektoren, Faktoren als auch Matrizen können zu einer Liste zusammengefasst werden. Diese Eigenschaften machen Listen zu einer der wichtigsten Datenstruktur in R. Eine Sonderform der Liste stellt der Dataframe dar.
Tipp zum Ausprobieren
Du kannst den hier dargestellten Code (alles nach dem>Symbol) mit der Maus markieren, kopieren und in R einfügen. So kannst Du die hier vorgestellten Inhalte noch einmal in R nachvollziehen.
Um eine Liste zu erstellen werden die Werte zunächst zugewiesen:
> Baumart <- c("Betula", "Acer", "Quercus", "Prunus", "Alnus") # hier werden Character Werte zugewiesen
> Baumart
[1] "Betula" "Acer" "Quercus" "Prunus" "Alnus"
> Hoehe <- c(1.5, 3.6, 7.5, 1.8, 4.9) # hier werden numerische Werte zugewiesen
> Hoehe
[1] 1.5 3.6 7.5 1.8 4.9
> z <- c(2, 4, 10, 2, 6, 3, 6, 9, 4, 7)
> Methode <- matrix(z, nrow = 2) # hier werden Integer Werte zugewiesen
> Methode
[,1] [,2] [,3] [,4] [,5]
[1,] 2 10 6 6 4
[2,] 4 2 3 9 7
Mit der Funktion list werden die Vektoren und die Matrix zu einer Liste zusammengefasst. Die Liste weist somit drei Elemente auf, in denen wiederum Character, numerische und Integer Werte enthalten sind. Anhand der [[]] ist ersichtlich, an welcher Position sich die einzelnen Elemente innerhalb der Liste befinden.
> Baum_Liste <- list(Baumart, Hoehe, Methode)
> Baum_Liste
[[1]]
[1] "Betula" "Acer" "Quercus" "Prunus" "Alnus" # Listen-Element an 1. Position der Liste
[[2]]
[1] 1.5 3.6 7.5 1.8 4.9 # Listen-Element an 2. Position der Liste
[[3]]
[,1] [,2] [,3] [,4] [,5] # Listen-Element an 3. Position der Liste
[1,] 2 10 6 6 4
[2,] 4 2 3 9 7
Die Funktion str gibt Aufschluss über die Struktur der eben erstellten Liste:
> str(Baum_Liste)
List of 3
$ : chr [1:5] "Betula" "Acer" "Quercus" "Prunus" ...
$ : num [1:5] 1.5 3.6 7.5 1.8 4.9
$ : num [1:2, 1:5] 2 4 10 2 6 3 6 9 4 7Wie bei Vektoren können die Elemente einer Liste mithilfe von eckigen Klammern aufgerufen werden. Mit [i] wird die i-te Liste innerhalb des Listen-Objektes aufgerufen. Im folgenden Beispiel wird das 2. Listen-Element angezeigt.
> Baum_Liste[2]
[[1]]
[1] 1.5 3.6 7.5 1.8 4.9 # Ausgabe erfolgt als ListeMit [[i]] wird das i-te Element innerhalb des Listen-Objektes aufgerufen. Dieses Mal erfolgt die Ausgabe nicht als Liste sondern als Vektor.
> Baum_Liste[[2]]
[1] 1.5 3.6 7.5 1.8 4.9 # Ausgabe erfolgt als VektorMit [[i]] [j] wird das j-te Element des i-te Elements innerhalb des Listen-Objektes aufgerufen. In diesem Beispiel wird das vierte und fünfte Element des ursprünglichen Vektors "Hoehe" aufgerufen.
> Baum_Liste[[2]][4:5]
[1] 1.8 4.9 # Hier wird der 4. und 5. Wert des Vektors "Hoehe" ausgegebenBeim Zugriff auf eine Matrix innerhalb einer Liste, ist [[i]] [j,k] und es wird das (j,k)-te Element des i-te Elements innerhalb des Listen-Objektes aufgerufen. In diesem Beispiel wird das erste und vierte Element der ursprünglichen Matrix "Methode" aufgerufen.
> Baum_Liste[[3]][1,4]
[1] 6 # Hier wird der Wert, welcher in der Matrix "Methode" in der 1. Zeile an 4. Stelle steht, ausgegebenIm Folgenden wird Dir gezeigt, wie Du mit Listen rechnen kannst. Es soll der Mittelwert für die einzelnen Listen-Elemente der Liste berechnet werden. Dafür wird die Funktion mean verwendet. Mithilfe der Funktion mean kann der Mittelwert der einzelnen Listen-Elemente nicht berechnet werden, da die Funktion nicht auf die einzelnen Listen-Elemente zugreifen kann.
> mean(Baum_Liste)
[1] NA # Die Funktion kann nicht auf die Listen-Elemente zugreifen
Warning message:
In mean.default(Baum_Liste) :
Argument ist weder numerisch noch boolesch: gebe NA zurückUm den Mittelwert berechnen zu können, wird eine Funktion benötigt, die auf die einzelnen Listen-Elemente der Liste zugreifen kann: lapply aus der apply Familie. Die Ausgabe erfolgt in Listenform in der Console. Für das erste Listen-Element der Liste (Baumarten) kann kein Mittelwert berechnet werden, da hier Character Werte hinterlegt sind. Es wird der Wert NA ausgegeben. Dieser Wert steht für not available. Für die anderen Listen-Elemente der Liste wird der Mittelwert berechnet und als Liste ausgegeben.
> lapply(Baum_Liste, mean)
[[1]]
[1] NA # Es ist nicht möglich für Character Werte einen Mittelwert zu berechnen
[[2]]
[1] 3.86 # Mittelwert des numerischen Vektors "Hoehe"
[[3]]
[1] 5.3 # Mittelwert der Matrix "Methode"Die Zuweisung zu einem Objekt speichert die Berechnung des Mittelwertes im Environment und macht die Ergebnisse für andere Funktionen verwendbar. Die Warning-Message weist auch hier wieder daraufhin, dass es für Character Werte nicht möglich ist einen Mittelwert zu berechnen.
> Mittelwert <-lapply(Baum_Liste, mean)
Warning message:
In mean.default(X[[i]], ...) :
Argument ist weder numerisch noch boolesch: gebe NA zurück
> Mittelwert
[[1]]
[1] NA # Es ist nicht möglich für Character Werte einen Mittelwert zu berechnen
[[2]]
[1] 3.86 # Mittelwert des numerischen Vektors "Hoehe"
[[3]]
[1] 5.3 # Mittelwert der Matrix "Methode"Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Dataframe
Ein Dataframe ist eine Kombination aus unterschiedlichen Zahlenformaten. Es ist vielleicht der wichtigste Datentyp in R, da bei der Erhebung von Messdaten oft solche Datenstrukturen vorliegen.
Die folgende Slideshow gibt ein Überblick über Dataframes.
-

-
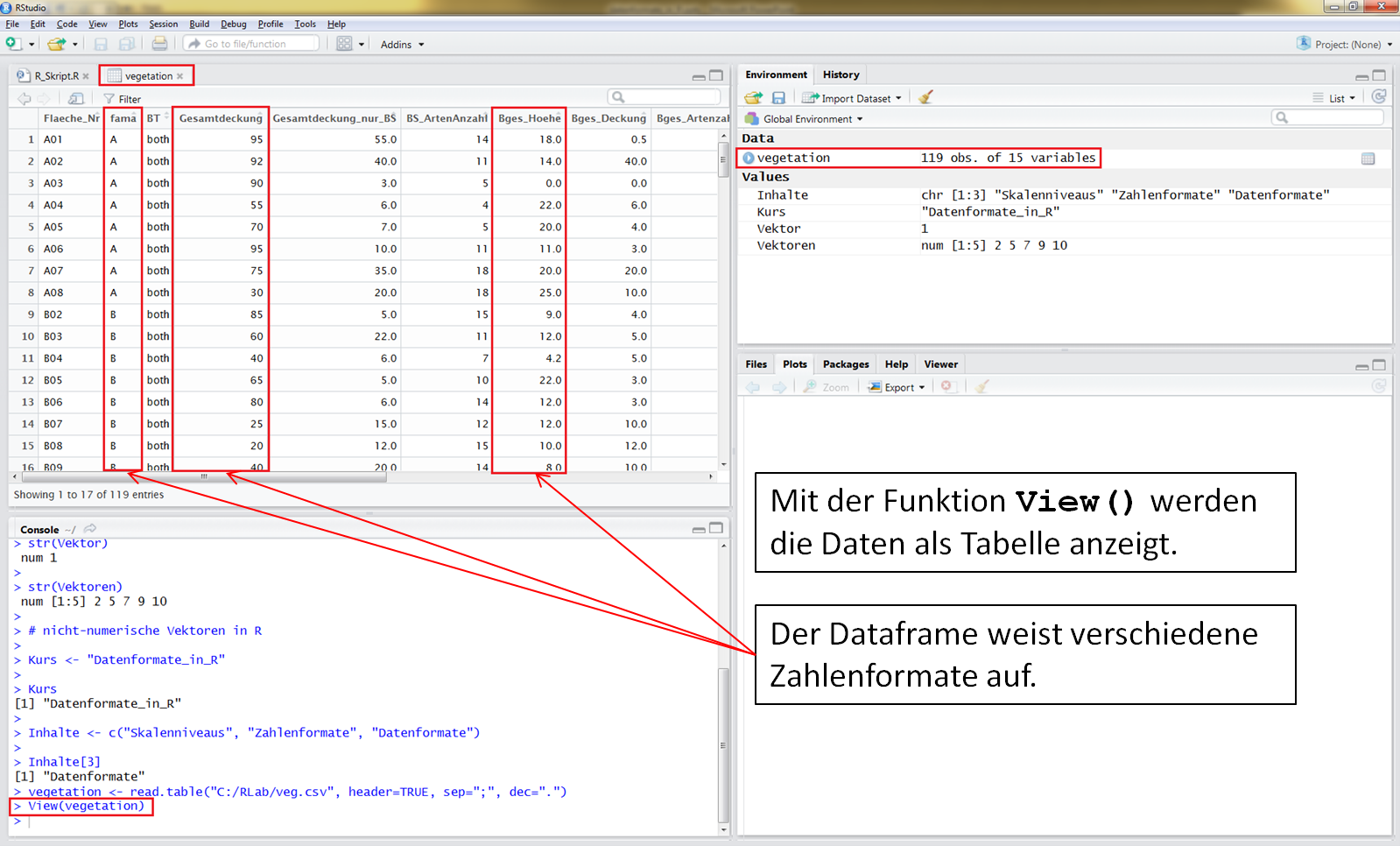
Die Werte innerhalb des Dataframes werden angezeigt.
-
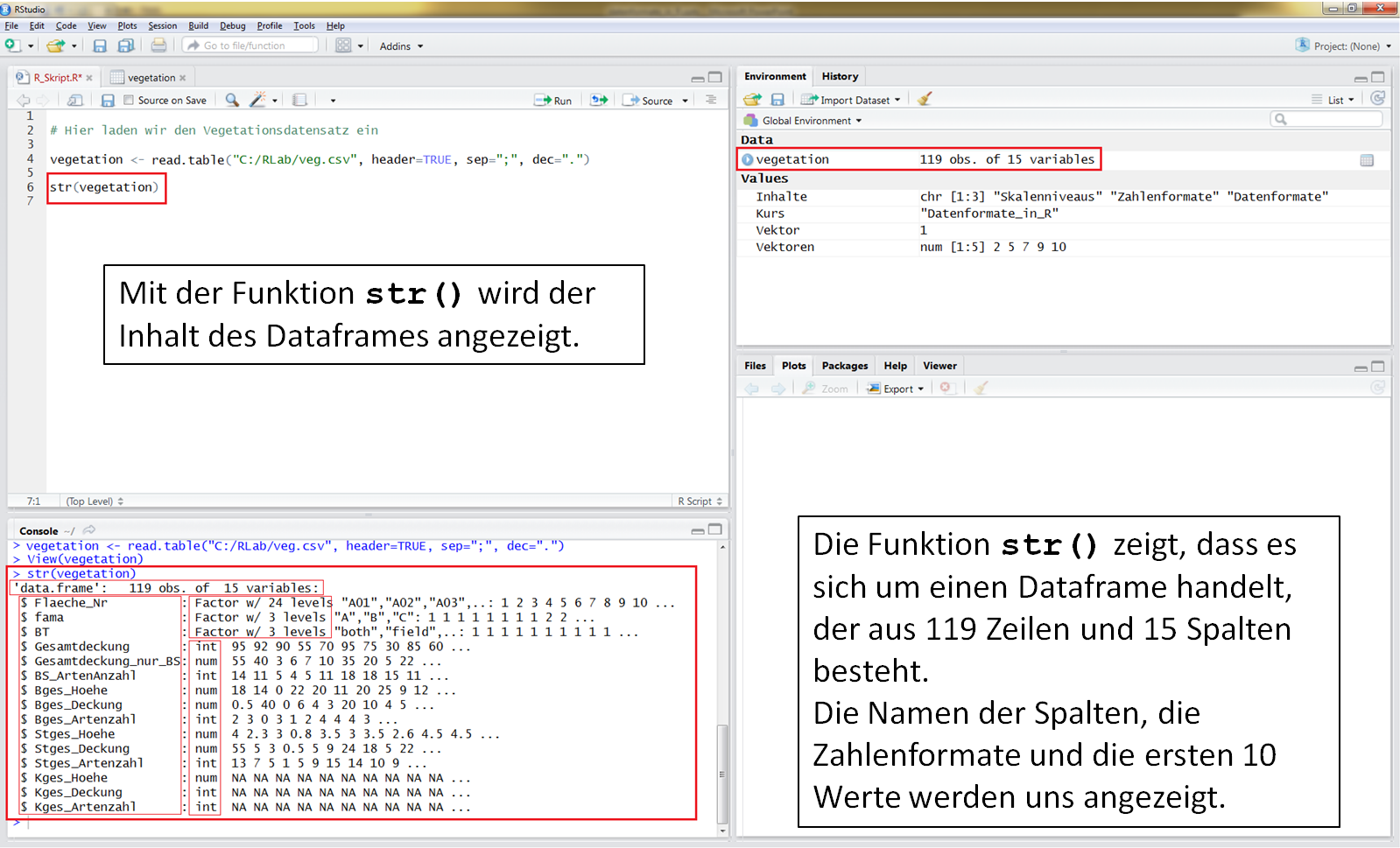
Hier wird der Inhalt des Dataframes angezeigt.
-
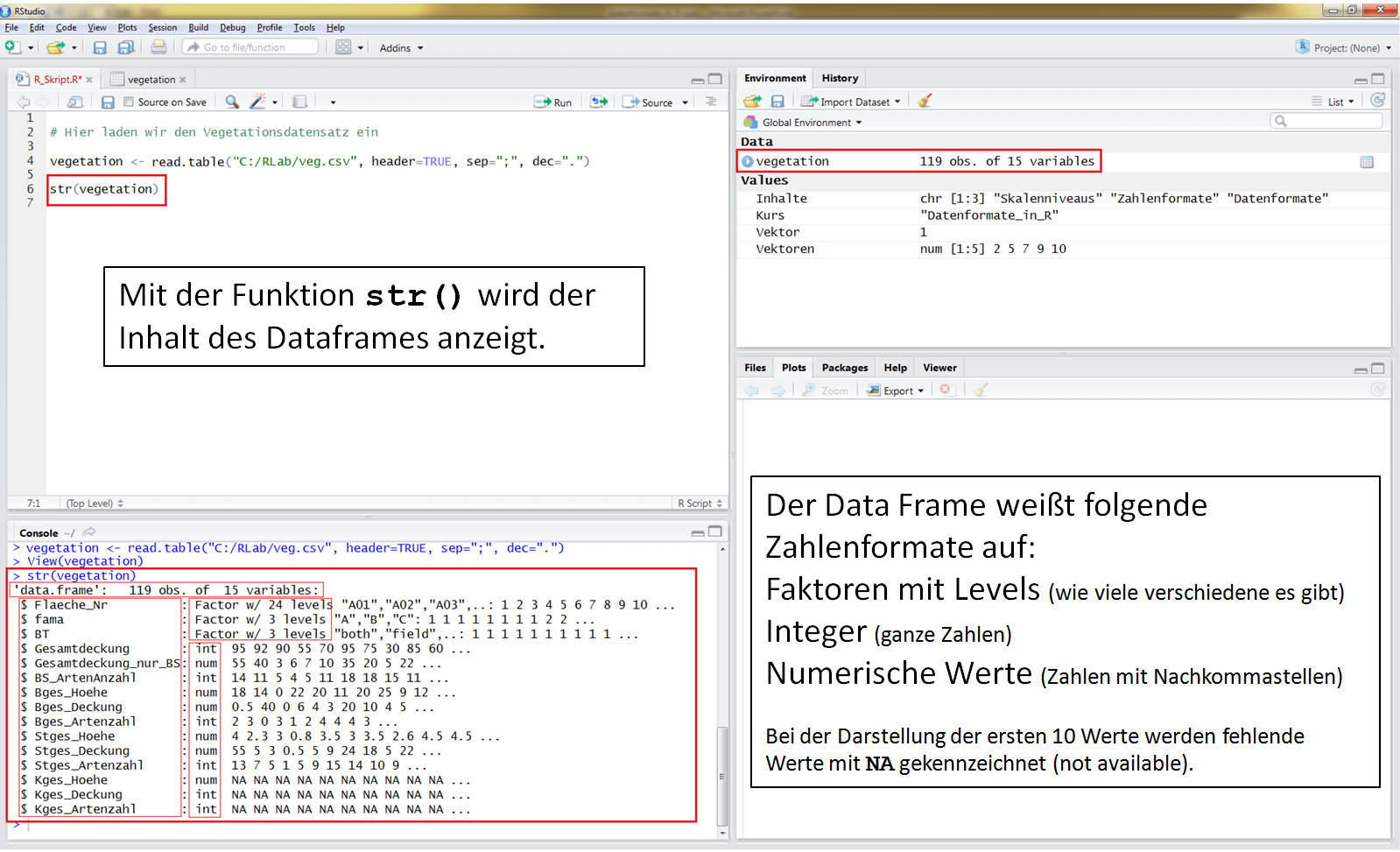
Mit der Funktion str() kannst Du Dir das Datenformat, die Zahlenformate der einzelnen Spalten und die ersten 10 Werte anzeigen lassen.
-
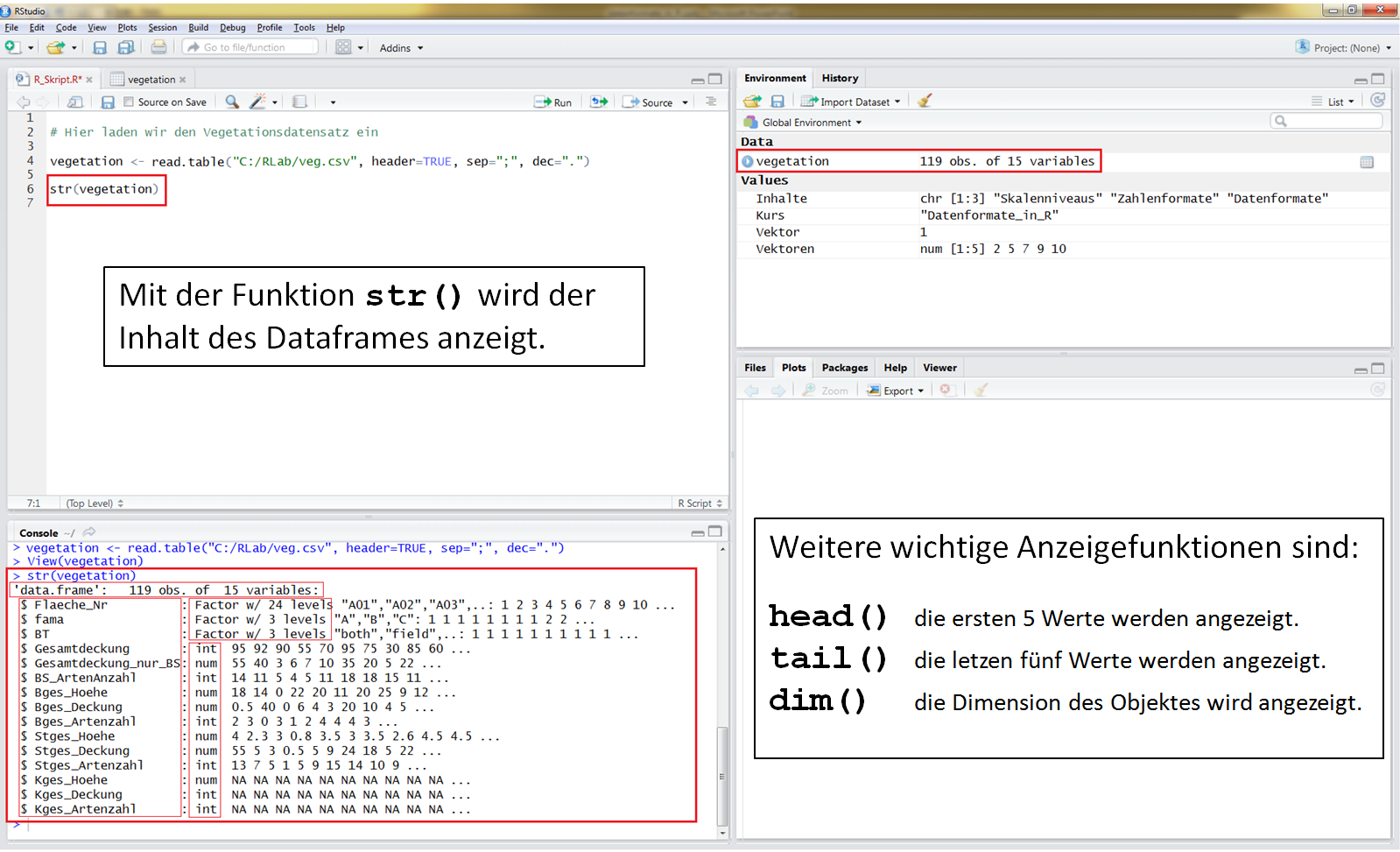
Weitere wichtige Anzeigefunktionen neben View() und str(). Bitte beachte, dass View mit einem großen V anfängt.
Den Vegetationsdatensatz kannst Du Dir hier als .csv Datei herunterladen.
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Objekte in R
Grundsätzlich ist alles in R ein Objekt.
Egal ob es sich hierbei um eine eingelesene Tabelle oder eine errechnete Zahl handelt.
Sobald etwas im Environment auftaucht, handelt es sich hierbei um ein Objekt.
Wie sich Objekte noch genauer differenzieren lassen, wurde anhand der verschiedenen Datenformate, die sich aus den Zahlenformaten zusammensetzen, auf den vorherigen Folien erläutert.
Es ist besonders wichtig zu verstehen, es unterschiedliche Datenformate gibt, denn davon hängen die Möglichkeiten der statistischen Auswertung ab.
Nicht jede Funktion kann mit jedem Datenformat rechnen, bzw. die geeignete Funktion muss für das entsprechende Datenformat herangezogen werden.
Zusammenfassung
In diesem Digitalen Skript hast Du gelernt welche Zahlenformate es in R gibt. Zahlenformate bestimmen das Datenformat und alle Datenformate werden in R als ein Objekt angesehen.
Abschließend wurde noch darauf eingegangen wie Du dir die Datenformate in R anzeigen lassen kannst.
Klappt etwas nicht wie gewünscht?
Schreibe Deine Frage als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Dir gefällt RLab?
Nimm dir ein R!
Alles ist besser mit einem R!