Skalenniveaus

Maria Bobrowski
RLab - Skriptbasierte modulare Umweltstatistik (Universitätskolleg 2.0)
Universität Hamburg
RLab-Impressum
Gefördert im Rahmen des „Lehrlabors“ im Universitätskolleg 2.0 aus Mitteln des BMBF (01PL17033)

Dieses Digitale Skript von Maria Bobrowski, Universitätskolleg 2.0 / Lehrlabor, Universität Hamburg, ist lizenziert unter einer Creative Commons Namensnennung - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz.
elearn.js Template
Universität Hamburg
Das elearn.js Template von Universität Hamburg ist lizenziert unter einer Creative Commons Namensnennung - Weitergabe unter gleichen Bedingungen 4.0 International Lizenz
Skalenniveaus
Maria Bobrowski
RLab - Skriptbasierte modulare Umweltstatistik (Universitätskolleg 2.0)
Universität Hamburg
CC BY-SA 4.0| 2017
Ziel
In diesem Skript erfährst, Du welche Skalenformate es gibt.
Am Ende werden Dir Hinweise zum Umgang mit den einzelnen Skalenniveaus gegeben,
zum Beispiel welche Berechnungen mit den jeweiligen Skalenniveaus durchgeführt werden können.
Für Anregungen und Kommentare zur Verbesserung ist das RLab-Team immer dankbar! Du kannst auch Fragen zu den Inhalten stellen! Nutze für all das gerne die Kommentar-Funktion!
Hast Du Fragen?
Stelle sie als Kommentar - das RLab-Team (oder andere Lernende) antworten!
Skalenniveaus
Eine Zahl ist nicht gleich eine Zahl.
Die Datengrundlage wird aus den beobachteten Ausprägungen der erhobenen Merkmale gebildet. So können die beobachteten Ausprägungen zum Beispiel die Baumart und die erhobenen Merkmale zum Beispiel die Baumhöhe (gemessene Werte) sein.
Danach entscheidet sich welche statistischen Methoden angewendet werden können.
Entscheidend für die Auswahl der Methoden und die Art der grafischen Aufbereitung ist das Skalenniveau eines Merkmals. Eine Skala ist eine Anordnung von Werten, denen die Merkmalsausprägungen eindeutig zugeordnet werden.
Es gibt verschiedene Skalenformate, auf die nun genauer eingegangen werden soll:
- Nominal-skalierte Daten
- Ordinal-skalierte Daten
- Intervall-skalierte Daten
- Verhältnis-skalierte Daten

Skalenniveaus
Nominalskala
Die Nominalskala ist die einfachste Form. Hierbei handelt es sich um Häufigkeiten von verschiedenen Merkmalen, bei denen es keine natürliche Reihenfolge der Skalenwerte gibt. Das bedeutet, dass sich lediglich bestimmen lässt, ob diese Werte gleich oder verschieden sind.
Beispiel: Farben (blau/gelb/rot); Studienrichtungen (Geo, Bio, BWL, Jura)
Ordinal skalierte Daten
Auf einer Ordinalskala können die Merkmalsausprägungen in eine natürliche Reihenfolge gebracht werden, es existiert immer eine Rangordnung. Es handelt sich hier um Häufigkeiten, die auf einer bestimmten Rangfolge beruhen.
Beispiel: Schulnoten (“sehr gut” bis “ungenügend”); Platzierung (“1. Platz” bis “3. Platz”)
Kardinalskala
Die nächsten zwei vorgestellten Skalenniveaus zählen zu der Kardinalskala und lassen sich in “Intervall-skalierte Daten” und “Verhältnis-skalierte Daten” differenzieren. Grundsätzlich lässt sich bei diesen Skalenniveaus nicht nur eine Rangordnung bilden, sondern auch eine Differenzbildung der Merkmalsausprägungen. Das bedeutet, dass ein Abstandsmaß (Metrik) zur numerischen Erfassung dieser Differenzen besteht.
Es handelt sich hierbei außerdem um reelle Zahlen.
Intervall-skalierte Daten
Es ist eine metrische Skala, die keinen natürlichen Nullpunkt und keine natürliche Einheit besitzt. Im Gegensatz zur ordinal skalierten Daten (Bsp.: Noten) können hier Differenzen bzw. Abstände verglichen werden.
Beispiel: Längengrad; Temperatur; Zeitskala (Datum)
Verhältnis-skalierte Daten
Dies ist ebenfalls eine metrische Skala, die einen natürlichen Nullpunkt, aber keine natürliche Einheit besitzt.
Beispiel: Entfernung; Geschwindigkeit; Alter
Rechenoperationen
Nachdem die Skalenniveaus vorgestellt wurden, soll nun auf die Rechenmöglichkeiten eingegangen werden.
Je nachdem, welches Skalenniveau vorliegt, sind nur bestimmte Rechenoperationen möglich:
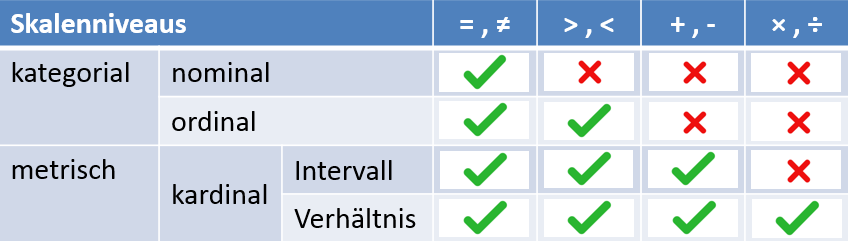
Zusammenfassung
In diesem Digitalen Skript hast Du gelernt welche Skalenniveaus es gibt und welche Rechenoperationen mit ihnen durchgeführt werden können.
Im Digitalen Skript zu Zahlenformaten und Datenformaten in R erfährst Du wie die Skalenniveaus in R bezeichnet werden.
Frage stellen?
Schreibe Deine Frage als Kommentar - das RLab-Team (oder andere Lernende) antworten!